

受惠 AI 浪潮的 DataBrick 看衰 GPU 將崩盤?
受惠 AI 浪潮的 DataBrick 看衰 GPU 將崩盤?
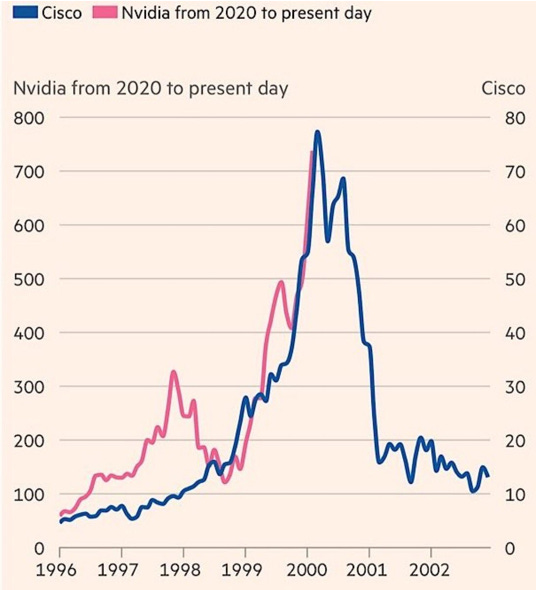
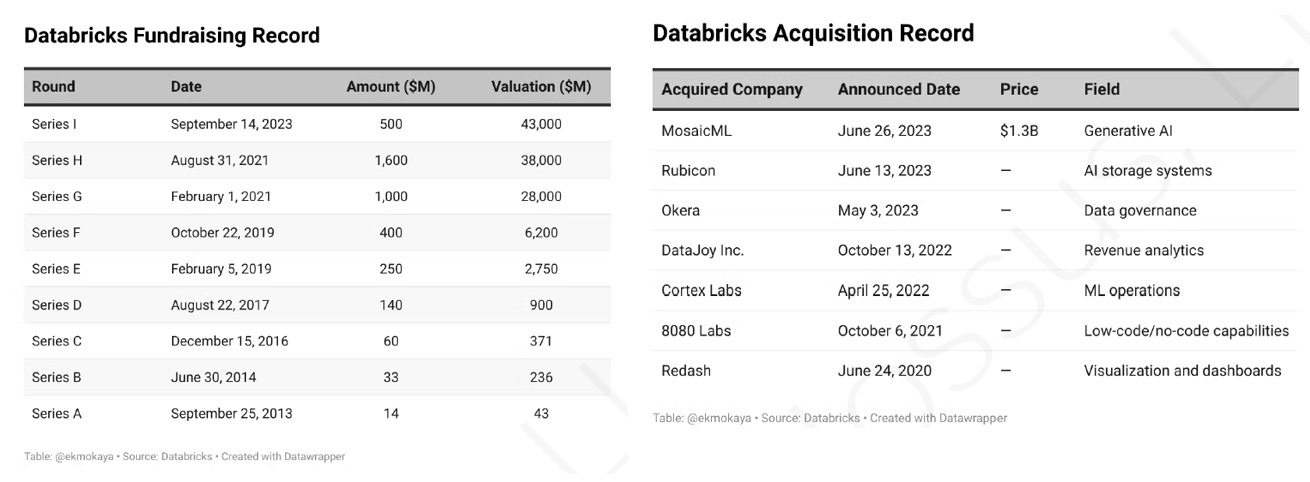
已從 NVDA 、MSFT 、 GOOGL 和 AMZN 成功募資、估值破 400 億 Databricks 的 CEO - Ali Ghodsi 將當前的 AI 熱潮比作 2000 年的網路泡破,並預言 GPU 價格很快就會崩盤,會帶衰 NVDA、CSP 與一票新創;有機會成為 AI 基礎建設的 Databricks, CEO 為什麼會看衰 GPU?來看看他的商業模式!

已從 NVDA 、MSFT 、 GOOGL 和 AMZN 成功募資、估值達 430 億 Databricks 的 CEO - Ali Ghodsi 將當前的生成式 AI 熱潮比作 2000 年的網路泡沫:
明年 GPU 晶片的價格將暴跌,將影響眾多大企業和新創公司的商業模式 - 幫助企業使用 AI ;正如網路頻寬限制在 2000 年消失一樣,GPU 也會有相同情況;
投資者和資金被 OpenAI 和其他領先的 AI 公司所吸引,投資人就像對 20 年前的路由器一樣興奮;但在大筆的資金投入之後,將讓 GPU 成為一種商品。
GPU 價格若急跌,恐損害那些已和主要雲端供應商租用多年 GPU 的新創,或也損害押注晶片將持續短缺的小型雲端供應商或 GPU 經銷商;當然也會影響 NVDA 。

【看圖說故事】
NVDA/GPU 的榮景可以持續多久,是熱門議題;Databricks 的 CEO - Ali Ghodsi 的說法在某方面難以否認,這些龍頭都有投資 Databricks ,同時也是其客戶,讓他講的話有某方面的特別意義;
然而,雖對 CSCO不熟,但 NVDA 除了 GPU 硬體之外,還有 CUDA 軟體,甚至還切入雲端服務,要成為所有 AI 應用的基礎建設,然後還投資一大堆的新創,並持續向各國政府推銷 AI 基礎建設,這都是過往 CSCO 沒有做到的;
現在就做結論說 NVDA/GPU 很快就不行了,似乎有點太快?讓我們持續看下去;
不過在此之前,還是先來介紹 Databricks ,或許其商業模式也可讓他成為全球的主要 AI 基礎建設供應商?
文章最後將附上 The Information 對 Ali Ghodsi 的專訪摘要
#AI 對軟體工程師和銷售人員的影響?
開源 #AI 模型將如何趕上 OpenAI ?
為何生成式 #AI 將激發新型穿戴裝置的靈感?
主講者: 來自於 SineWave 的 Yanev Suissa
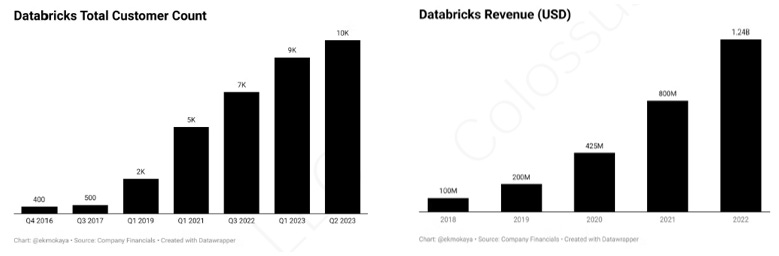
業務規模:
Snowflake 因獲得波克夏的投資而出名,原本是專精於結構化資料,但看到 Databricks讓企業可存取非結構化數據,正是目前 AI 熱潮最需要的技術,也開始發展非結構化數據技術;兩間公司皆已具備處理兩種資料的能力,並快速搶攻市場,而 Databricks 在 AI 的推波助瀾下而發展迅速、估值已達 430 億!
截至 2023 年第二季,全球有超過 1 萬 名企業使用其服務,包括Burberry、AT&T、Nasdaq、HSBC、Adobe、Absa、Walgreens、US Airforce、ABN-Amro、Sam’s Club、Warner Bros Discovery 和 Air Canada,超過 300 間的客戶都花費都超過 100 萬美元
截至 2023 年第二季, 年化營收已達 15 億美元,訂閱方案的毛利率為 85%;

基本介紹:Databricks 是一個資料處理平台;
所謂資料,可概分為結構化資料和非結構化資料;
結構化:有組織、格式化的資料,儲存在資料庫和表格中,可很輕易搜尋、處理、分析,並從歷史數據找出資訊。
非結構化:新的即時數據一直在產生;做決策時,需參考現況,譬如社群媒體發生的一切事情;除非擁有管理非結構化資料的獨特演算法或專業知識,否則很難篩選出有用的資訊,Databricks 因此開始涉足非結構化資料領域。
Databricks 讓企業可存取非結構化數據,而 Snowflake 專精於結構化資料,但現在兩間公司都已可處理結構化資料與非結構化資料。
舉例來說:
製造工廠:Databricks 與 Honeywell 合作,複雜的生產線上即時生產產品,不僅需要從機器中獲取數據,還要從廠內的感測器獲取數據,利用生產線及其工作人員的視訊監控來做決策,Databricks 可處理即時非結構化的串流資料。
石油探勘產業: Shell 利用 Databricks 監測 2 億個閥門的感測器數據,預測閥門是否會損壞,及時提前更換,保持系統運作、節省資金並確保員工安全。
新藥開發:Regeneron使用機器學習演算法檢測 DNA中引起慢性肝病的基因,並開發針對此基因的藥物。
銀行:須在欺詐發生的當下,觀察到端倪才能即時做出決定;
投資公司:分析全球衛星數據,预测哪些產業或公司值得投資。
社群網站的推薦系統 (AI 推論):消費者正在某網站查詢資料,平台可即時決定提供哪些廣告或推薦哪些內容,是為廣告主即時贏得潛在買家的最佳機會,廣告主會因此願意支付更高的價格,因為有更高的命中率。
過往,並沒有這種分析即時資料 (streaming data) 的能力,必須花時間深入研究數據,並拿出分析報告,才能了解哪些行動可以提高回報;但現在有越來越多的公司,都在利用數據即時做出決策, 這是 Databricks 為市場帶來的革命。
簡單來說, Databricks 能加速成長是因為可以即時滿足顧客的需求
數據分佈在不同的地方,又來自越來越多的地方:企業需以有意義的方式快速處理這些數據,以做出決策,尤其是疫情期間造成的供應鏈問題,讓企業體認到重要性;
AI 的擴展:多數人現在每天都在使用AI,只會持續增加,是即時分析非結構化數據讓 ChatGPT 成為可能。如果你問 ChatGPT 一個問題,需要一個小時後才能知道答案,不會有人對 ChatGPT 感到興奮。

假設 (Assumption):
數據呈爆炸性成長,需要適當的工具和功能,才能從中獲取最大的價值:企業未來能否有效地從數據中獲取價值將在很大程度上決定其數位化業務的成敗;為了盡可能從數據中提取價值,數據分析、AI 和 ML 正在不斷創新;
客戶想要提高決策效率:客戶的決策效率提高,花在雲端等基礎建設的費用將跟著減少,但會增加使用 Databricks 的次數,因其服務可以提高投資報酬率;對Databricks而言,因按使用量付費,為 Databricks 帶來更高的營收;對客戶而言,雖然會按需付費的成本會增加,但因為省去更多基礎建設的費用,又增加決策效率,實際上 投資報酬率是增加的;
商業模式 (Business Model):致力於透過結合資料倉庫( Data Warehouse)和資料湖 (Data Lake) 的優點,簡化和普及化資料管理。
針對不同領域推出不同的產品線:包括訂閱方案、企業解決方案、諮詢和專業服務和第三方交易市場;
獲利模式:吸引需要處理大量數據,但不想投資昂貴的硬體或軟體的企業
基本上為按需付費,即按使用量收費、即用即付的模式 (pay-as-you-go model);
訂閱制,並讓使客戶能夠根據需要,按月付費使用平台的高級功能,。
依即時數據 (streaming data) 做出分析與決策: 這是由 Databricks 創建的新產業;
策略(Strategies):
開放平台兼容性,成為每個人都可以進行分析的民主化平台:
不僅支持 Spark ,還允許其他分析工具在其平台上運行,使其成為一站式平台,滿足更多分析需求,吸引更多用戶。
不強迫企業用戶調整需求,而是提供可訂製的基礎設施和工具,以滿足多樣化要求;
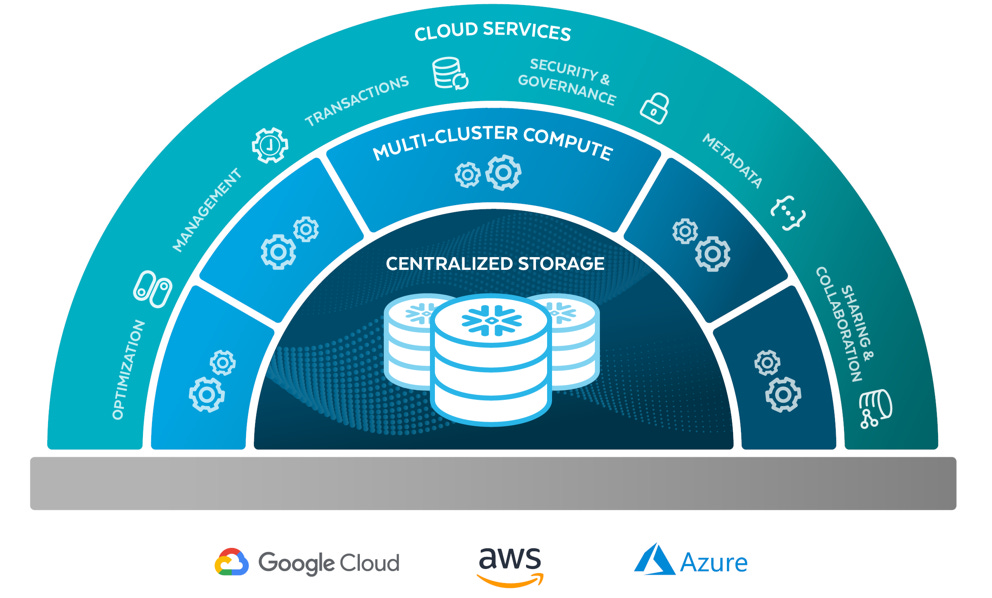
拓展平台的功能:善於處理即時數據 (streaming data) ,引入 湖屋 (Lakehouse) 概念,去結合 資料倉庫( Data Warehouse) 的結構化優勢和 資料湖 (Data Lake) 的可擴展性優點,為即時數據分析提供高效平台;並進一步支持 AI、LLM 等模型,允許用戶使用其他模型甚至自行開發模型,滿足其分析需求。
資料湖 (Data Lake):儲存大量資料的中央儲存庫,這些資料可以是結構化、半結構化或非結構化,通常用於儲存來自各種來源的資料;優點是可擴展、可存儲多種資料類型,但缺點是難以存取和分析、資料可能不一致或不完整;
資料倉庫( Data Warehouse):資料為結構化,是以主題為導向的資料儲存庫,主要用於商業分析,優點是一致性高、易於分析,缺點是成本高、難以擴展;
湖屋 (Lakehouse):結合 Data Lake 和 Data Warehouse 的 資料管理系統,資料型態為 結構化和半結構化,主要用於商業分析;可以兼具 Data Lake 和 Data Warehouse 的優點,但缺點是相對複雜與昂貴;


Databricks 進軍 AI 領域:
Databricks 長期服務 Fortune 500 企業,擁有企業級應用的優勢,因為 Databricks 具備高安全性,符合金融、醫療、公共部門等高度監管行業的要求,並切實地解決營運上的問題;
就 AI 而言,Mosaic 是 Databricks 朝向 AI 和 LLM 領域的重要嘗試,將其 LLM 與企業內部專有資料結合,並整合 Databricks 的安全性優勢,讓企業用戶可以控制數據,解決使用 AI 可能造成的數據洩漏和控制等問題;不過,客戶不會被限制使用其 LLM - Dolly,而是可選用平台上數百個模型;
Databricks 允許在其平台上使用所有不同類型的模型進行商業執行和使用,但也允許將其與企業自有資料整合,或是建立自有模型;開放平台的優勢,讓其他 AI 解決方案供應商都能夠上架其服務,能為企業客戶提供更多的 AI 解決方案,交由客戶自己選擇,不是像 AAPL 和 ORCL 這樣的封閉式平台讓客戶綁手綁腳;

跟同業的比較 ,Databricks 所建構的流量分析技術 (streaming analytics technology)、能力以及用於治理、安全性和整合的工具集超出其他公司,渴望打破其他公司所依賴的一些具黏性的網路效應。
與雲端供應商相比:
AWS、Google Cloud、Azure 也都提供大數據分析和 AI 服務,但其平台上也都有 Databricks 的產品與服務,彼此的關係既合作也競爭;
換個角度來想,因為 Databricks 讓企業客戶有效地使用數據和解決方案,或導致 AWS 或 Azure 等雲端基礎建設的使用量變少,但也有可能為他們帶來更多的客戶,畢竟資料還是要儲存在雲端;
與 Cloudera 相比:
技術架構:Databricks 是基於 Spark 的技術,Cloudera 是基於 Hadoop 資料處理框架的企業;
處理數據的方式不同:
Hadoop 分析資料的方式為批次操作,如單次整理一本書的資料;
Databricks 透過加速記憶體的處理能力 ,可以一次處理整間圖書館的藏書,速度更快、用途更廣泛、使用更容易,因此具有成本效益,且具備即時功能,能即時根據數據做出決策。

與 Snowflake 的差異:
雖然產品從功能角度來看非常相似,但 Snowflake 始於結構化環境,是分析文件和歷史數據的雲端底層基礎設施,Databricks 始於即時環境中的非結構化資料,;
不過,疫情期間產生的供應鏈問題,許多行業都需要進行即時決策,讓 Databricks 有了發揮的空間;
自從 ChatGPT 出現後,因為AI 基本上就是需要非結構化資料分析,Snowflake 雖也具備分析非結構化資料的能力,但 Databricks 更強,如果想要即時回應或視覺辨識,都需要即時分析非結構化資訊,就需要購買 Databricks 的服務;
Snowflake 則變成提供 AWS 或 Azure 那樣的底層基礎設施,可以在上面購買其他服務來執行非結構化資料的分析;
管理階層 (Managements):2013 年創辦 Databricks 的 7人都還是主要的高階主管;
")
Ali Ghodsi (左):Co-Founder,先任工程與產品經理 VP,2016 年轉任 CEO
出生於伊朗,於 1984 年隨家人移民瑞典,逃避伊朗革命;
九歲開始寫程式,14 歲靠為親友修理電腦來賺錢;移民美國前,曾在 Royal Institute of Technology 擔任副教授,在瑞典創立 Peerialism AB 軟體開發公司;
Mid-Sweden University 的 Computer Engineering 碩士學位與 MBA in Logistics & Strategic Marketing;
瑞典 KHT/Royal Institute of Technology 的 Distributed Computing 博士學位;
Matei Zaharia (中) : Co-Founder,自 2013 年起擔任 CTO,主持 Delta Lake、MLFlow 和 Dolly 等項目;
2009 年在 University of California 攻讀博士期間,遇到 Ali Ghodsi ,並連同其他五人在 University of California 的Algorithms, Machines & People Lab (AMP Lab) 成立開放源碼項目 - Apache Spark;
Ion Stoica (右) :Co-Founder,2013 - 2015 年任 CEO, 2016 年轉任執行董事長
自 2009 年起,他一直是 UC Berkeley 的 EECS Department 的教授,同時也是該校 Algorithms, Machines & People Lab (AMP Lab) 的 co-director;
Carnegie Mellon University 的 Electrical & Computer Engineering 博士學位;
Polytechnic University 的 Computer Science & Control Engineering 碩士學位;

歷史:
來自 UC Berkeley AMP Lab 的 Databricks,其提供的工具,可用來擷取、轉換和分析來自多來源、多格式的大量資料,進而提供有用的資訊來協助客戶做出決策,Databricks 讓企業可存取非結構化數據,而 Snowflake 專精於結構化資料,現在兩間公司都有在處理結構化資料與非結構化資料。
2013 年,Databricks 誕生於 Ion Stoica 教授的 AMP 實驗室,是由 Ion Stoica 與 Matei Zaharia、Ali Ghodsi、Patrick Wendell、Reynold Xin、Arsalan Tavakoli-Shiraji 和 Andy Konwinski 等 7 個人共同創立 Databricks,這七個人至今都仍是 Databricks 的高階主管;
初期開發 Apache Spark 開源軟體,並從中開發出自有 Spark 版本,性能更快、成本更低、更有效;後來獲得 1400 萬來自於 A16Z 的資金。
2014 年,推出基於 Apache Spark 開源軟體的雲端平台 - Databricks Cloud;允許企業在可控的環境中使用最佳的 Spark 功能, B 輪募資又獲得 3300 萬美元的資金;
2015 年,與 AMZN 合作,整合 Spark 與 AWS 基礎建設,方便企業客戶 在 AWS 雲端平台使用 Databricks。 2016 年 再與 MSFT 達成類似協議;
2017 年,推出統一數據管理系統 - Delta,以解決當時在資料管理上遭遇的挑戰,因為串流處理系統(streaming systems)、資料湖(data lakes)與資料倉庫(data warehouses)等不同系,統導致資料管理工作變得更加困難和複雜;Delta 可以簡化跨多個不同系統的大規模資料管理工作。
2019年,MSFT 參與 E 輪融資;
2020,收購 Redash,為其資料湖 (data lakes) 帶來可視化功能。
2021 年,Baillie Gifford 參加 H 輪融資,估值達 380 億美元;
2023 年,I 輪融資後,估值達 430 億美元;
收購 MosaicML、Rubicon 和 Okera;
推出 小型的開源 LLM - DOLLY LLM,
與 Salesforce 合作,將 CRM的Data Cloud 與 Databricks 的 Lakehouse 整合。
The Information 對 Ali Ghodsi 的專訪摘要
The Information:生成式 #AI 新創的機會在哪?什麼有效,什麼無效?
Ali Ghodsi:
人們認為網路有巨大潛力,資金進入各種新創,然後泡沫破滅。 人們後來發現路由器只是一種商品,不是很有趣,認為基礎模型也是一樣,最終將降至以成本價出售。
基礎設施層將賺很多錢,好比 #AI 的 AWS,是所有在其上建立 #AI 的企業的基礎設施提供者,這是 Databricks 的大賭注。針對消費者和企業的應用程式將有很大的價值,但現在還不知道它是什麼。
2000 年時無法預測 Twitter、Facebook、Airbnb 或 Uber ,但它們確實都發生了,成為非常有價值的巨型公司,那麼這次會出現哪些?
The Information:#AI 新創遇到的最大挑戰?
Ghodsi:
在此 #AI 浪潮前就獲得融資的新創的最大挑戰是收入模式 - 賺錢嗎?部分有大量使用量和用戶,但可將其貨幣化嗎?
如何真正有用?如何夠可靠?如何確保擁有最新資訊?,讓人們每天使用它、並且沒有錯誤?
隱私、安全和監管,存在著許多不確定性,人們並不像現在這樣關心這些事。
The Information:哪些公司做對了?
Ghodsi:
$MSFT 是贏家,但模型來自 OpenAI ; OpenAI 是否會繼續生產最先進的模型,是否還會向 $MSFT 提供模型權重(或確定模型如何回應的設定)?將非常重要;將 IP 送給擁有全球最大企業銷售團隊的公司,這將是一種有趣的關係。
我是 Perplexity 的忠實粉絲,Perplexity 確實改善用戶體驗,但並未像 1 年前所期望的那樣真正改變生活。
具有挑戰性的是,許多新創都是從一種奇怪的融資或 GPU 承諾模式開始的,這會為其未來帶來額外的挑戰,未來 12 個月將看到很多動盪。
The Information:更深入地討論?
Ghodsi:
購買 GPU是為 Bitcoin 挖礦,而 Ethereum 改變模型就不再需要 GPU,但發現 OpenAI 正用 GPU 訓練模型,每個人又都搶著購買 $NVDA 的 GPU,2000 年也出現過如此瘋狂的稀缺現象,但資本主義解決此問題,頻寬價格暴跌,GPU 也會發生同樣的事情。
進行「GPU money laundering」的新創,僅為購買 GPU 就須籌集數億而推高估值很高。價格下降會如何影響這些已 GPU 做出三年承諾的新創?這對任何過度投入 GPU 的人來說都是一個巨大的挑戰
The Information:但 Sam Altman 想要數兆美元來克服 GPU 瓶頸?
Ghodsi:
有幾家公司真正相信,投入的 GPU 和資金越多, LLMs 就會越好。
第一個問題是,隨著模型開源,沒有人需要 GPU 進行預訓練,又有多少公司需要花大錢?
第二個問題是,LLMs 變得更聰明並不重要,而是要對企業和用戶想要的任務真正有用,有其他重要因素,如合成資料、品質、系統。自駕車不會只培養最大的 LLM,不會僅是投入更多 GPU
The Information: Databricks 與 $MSFT 關係密切,如何平衡合作與競爭?新創該如何處理這些關係?
Ghodsi:
$GOOGL、$AMZN、$MSFT 等雲端公司都是 Databricks 的投資者,都有良好的關係。在產品層面則有競合關係,這是常態
創始人多想成為下個 $GOOGL,但請特別保護 IP,這確實是長期與短期的權衡。
很多人現在都想要短期收入,從雲端獲得收入是有幫助的
但若想要長遠,就需保持獨立,一家可持續發展的公司需要有大量客戶
The Information:就你從 Apache Spark 創建 Databricks 的經驗來看,開源模型要多久才能追上現有最先進的模型?
Ghodsi:
現有最好的開源模型的表現,都會向下與 GPT-4 靠攏,因為每個人都是抓取整個網路的開放資料,最終變成商品化;
如果能有別人沒有的資料,這將是優勢,這就是 Databricks 所做的,Databricks 收購 Mosaic ,Mosaic 有非常專業的數據集,Databricks 為該數據集建立模型,讓他們保留權重和模型;
對企業特定用例進行微調時,Databricks的內部模型都能擊敗現有的所有模型;Databricks 是在作弊 - 用企業提供的特定任務的數據去調整模型、或為該任務建立客製模型,才能每次都擊敗對手;
想像想擁有自己的 #AI 醫生,這需要一家非常專業的公司,這不太可能是像 OpenAI 這樣的基礎模型提供者
The Information: 有生成式 #AI 和程式助理之後,五年後還會有相同數量的軟體工程師、銷售人員嗎?
Ghodsi:
這一兩年人們變得有點極端。
人類將始終參與其中。這項技術確實增強人類的能力。如果能夠更容易、更便宜地編寫軟體,會有更多的人想要寫軟體。
這是一個基本的供需論點,我們不會因此而減少招募軟體工程師,需求仍然比以前多。
在銷售方面,將會發生很多自動化。因此,看看我們的收件匣會發生什麼以及將來誰會閱讀這些收件匣將會很有趣。是人類還是其他人?
企業銷售則沒有太大的改變。因為讓銀行以上千萬美元的價格購買軟體是個關係問題。必須要讓 CEO、CTO 相信這是一項很好的技術,讓安全團隊相信它是安全的,涉及人際關係。
The Information: LLM 將作為下一個作業系統,為許多不同設備提供支援,你怎麼看?
Ghodsi:
人們總是想用更多GPU來訓練更大的模型,但模型越大,提供服務的成本就越高,並離邊緣設備越遠。
重點應該是如何讓小型模型變得更聰明。過去因為 Google 一篇論文誤導大家認為必須訓練更大模型,但實際上可以透過不同技巧讓小模型也很聰明,並且適合部署在邊緣,甚至不需要專用硬體就可以提供服務
LLM 將是一場使用者介面革命,人們將透過交談與許多事物互動