

How Apple's iPhone Uses Private, On-Device Machine Learning To Recognize People In Photos
How Apple's iPhone Uses Private, On-Device Machine Learning To Recognize People In Photos
Learn how contrastive learning, embeddings and clustering recognize people across a diverse demographic.

Get a list of personally curated and freely accessible ML, NLP, and computer vision resources for FREE on newsletter sign-up.
To read more on this topic see the references section at the bottom. Consider sharing this post with someone who wants to study machine learning.

With 2 billion active devices, Apple has cemented its place in the consumer marketplace.
More than 4.7 billion photos are taken daily with an average person taking around 20 photos [5].
With so many photos, Apple (and Google Android) have developed machine learning-powered features to help users navigate through photos captured on their smart devices.
0. The Rise of Smartphone Photography
Smartphones are the go-to device for photography enthusiasts because they offer convenience and an entire photo studio in your pocket. You can snap, edit, and share photos instantly.
Smartphones make photography effortless, leading to a massive amount of user-generated content. To handle this data effectively, machine learning (ML) powered features need to be robust and on the cutting edge of tech.
Apple and Google have built features to automatically organize photos, create albums, and remove duplicates. One such feature that uses ML at its core is recognizing people using visual cues from images.
1. Scoping The Problem
Apple uses on-device machine learning to recognize people in your photos. Using machine learning they provide powerful exploration and automation features to users.
Browse by Person: Tap a person's face in a photo to see all their pictures.
Search by Name: Type a person's name to find photos of them.
Memories: Automatically create videos showcasing moments with important people in your life.
All this happens privately and on the device, keeping your photos secure.
Varying Photographic Styles: People capture moments differently depending on age and culture. Younger users are more likely to use photos for self-expression and sharing on social media while older users use photos more for personal archiving [6]. The algorithm needs to work equally well on selfies and family photos.
Change Appearances: A more challenging part is the varying appearance of the same subject across photos. A single subject can appear in different poses, sizes, lighting, clothing, hairstyles, and makeup. With multiple subjects involved, there are even more moving parts. Visual appearance varies widely with age, gender, and skin color making the problem harder.
Benchmarks mimicking real-world usage: With billions of users worldwide, Apple can't test their photo detective on everyone. Instead, they create special "benchmarks" - curated sets of photos representing diverse demographics and usage patterns. Think of a college student's photo library compared to a parent of three young children. These benchmarks ensure the system works well across user groups.
Apart from these, since Apple is serious about user privacy, they have additional constraints on the deployed solution:
Private, on-device, efficient: A model1 that is lightweight and efficient. It should have minimal memory and battery consumption.
Scalable: Works well on both small and large numbers of images in a user’s library.
Incorporate user feedback: No system is perfect but its efficiency can be improved using human-in-the-loop. Users can provide manual labels or correct wrong suggestions made by the model. This additional supervision for the model is worth its weight in gold.
2. Faces and Beyond
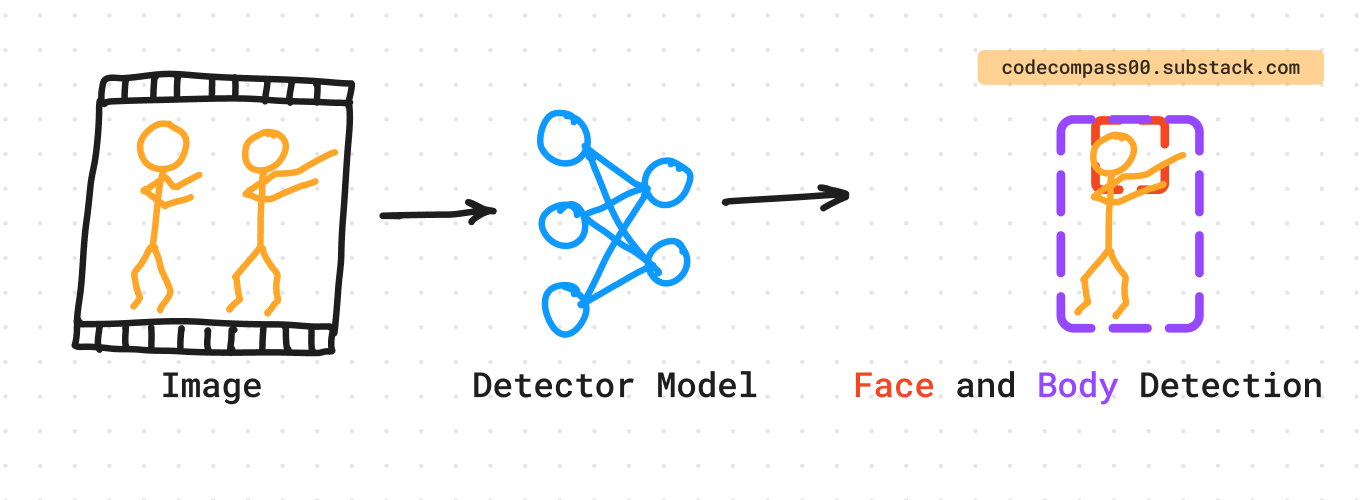
The ML system does not just look at faces but also the body. Object detection is performed to detect (1) the face and (2) the upper body of all subjects in a photo [3].
The upper body provides strong visual cues when the face is occluded or turned away from the camera. Assuming consistency of clothing and appearance cues (such as beard, hairstyle, head-gear, etc.) the “appearance” of the upper body helps recognize and connect the same subject across multiple photos.
Faces and upper bodies are matched using overlap between bounding box pairs.
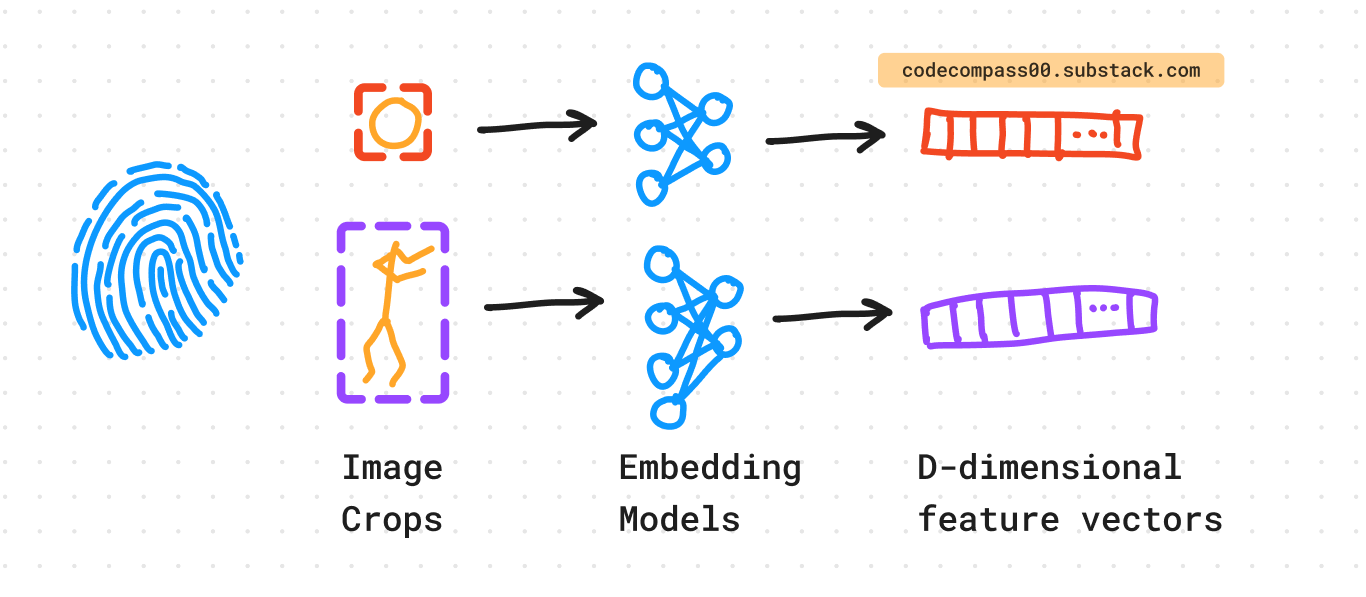
3. Generating Fingerprints For Faces and Upper Bodies
Each detected face and upper body is cropped and fed through different pre-trained embedders. The embedder is a pre-trained2 CNN (more on that later) using contrastive learning [14].
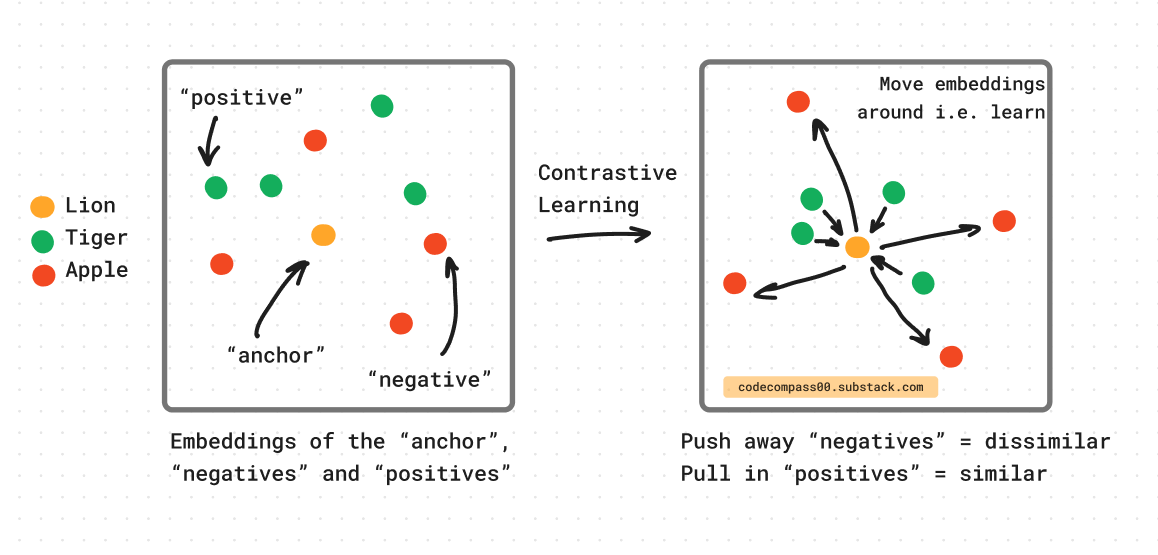
Contrastive learning involves training a model to take an input and output a feature vector. The distance of the input feature vector to feature vectors of similar objects (“positive” samples) should be smaller than its distance to feature vectors of dissimilar objects (“negative” objects). After training, the model should learn a function that maps similar objects closely in high-dimensional space forming clusters of these similar objects.

4. Recognizing Subjects
When a subject is observed, its (1) face and (2) upper body are passed through the feature extractors to generate feature vector fingerprints also known as “embeddings”.
For each newly acquired image, faces and bodies are detected and their corresponding D-dimensional embeddings are stored in a “gallery”. As mentioned previously, the embedder clusters objects with similar visual cues together. Each cluster corresponds to different people that appear across the photos on the device.
A novel iterative clustering algorithm is used to assign identities to observed subjects.
The assumption of consistency of clothing is only valid for a short time window at a specific location. The upper body embeddings can change due to a change of clothing at a later time. With this in mind, upper body embeddings are only “valid” for photos taken at the same location within a short time window. The time and location are metadata are taken from the capturing device.
The information from the face and upper body are combined using a weighted distance metric. The scalars alpha3 and beta are tuned [3].
The feature vector in the high-dimensional space is used to (a) assign the observed subject to an existing identity in the “gallery” or (b) create a new identity. The latter usually occurs when the observed subject is too dissimilar from existing identities in the “gallery”.
5. Clustering Observations Into Identities
Periodically, the system runs clustering on new and old observations. This allows the system to recognize new observations. A variant of hierarchical agglomerative clustering (HAC) [4] is used which involves multiple steps of clustering.
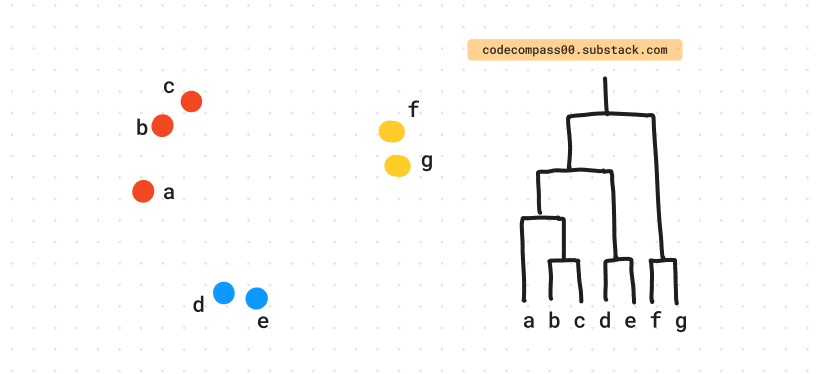
a. Initial Clustering Step
To create many small but high-precision clusters, the initial clustering is designed to be conservative. This is done by tightly coupling together face and body embeddings. Subsequent clustering steps only use the face embeddings and drop the body embeddings [3].
b. Subsequent Clustering Steps
The algorithm merges a cluster with another candidate cluster that has the smallest has the smallest median distance between all pairs of data points in the two clusters.
This is a variation of the more common linkage strategies like single linkage (minimum distance between all pairs of points), complete linkage (maximum distance between all pairs of points), and average linkage (average distance between all pairs of points) [4].
Median linkage is a great choice in the context of clustering to create identities of subjects:
Median linkage is more robust to outliers compared to average linkage. Robustness comes from the median being less affected by extreme distances between individual data points. If there is an outlier in a cluster due to noisy embeddings or sampling (see Sampling to Improve Efficiency below), the median value would be affected minimally.
It produces compact and spherical clusters compared to elongated clusters using single linkage.
Sampling to Improve Efficiency
For computational efficiency, sampling is performed when merging 2 clusters with a large number of points. Instead of computing distance for all pairs in both clusters, points are sampled randomly.
Given a large enough sample size it should approximate the actual median distance closely. As mentioned above, using the median instead of the mean makes it resistant to noise that may occur due to the sampling process.
Their implementation has custom optimizations to maintain the runtime and memory footprint of single linkage and performance on par with average linkage [3].
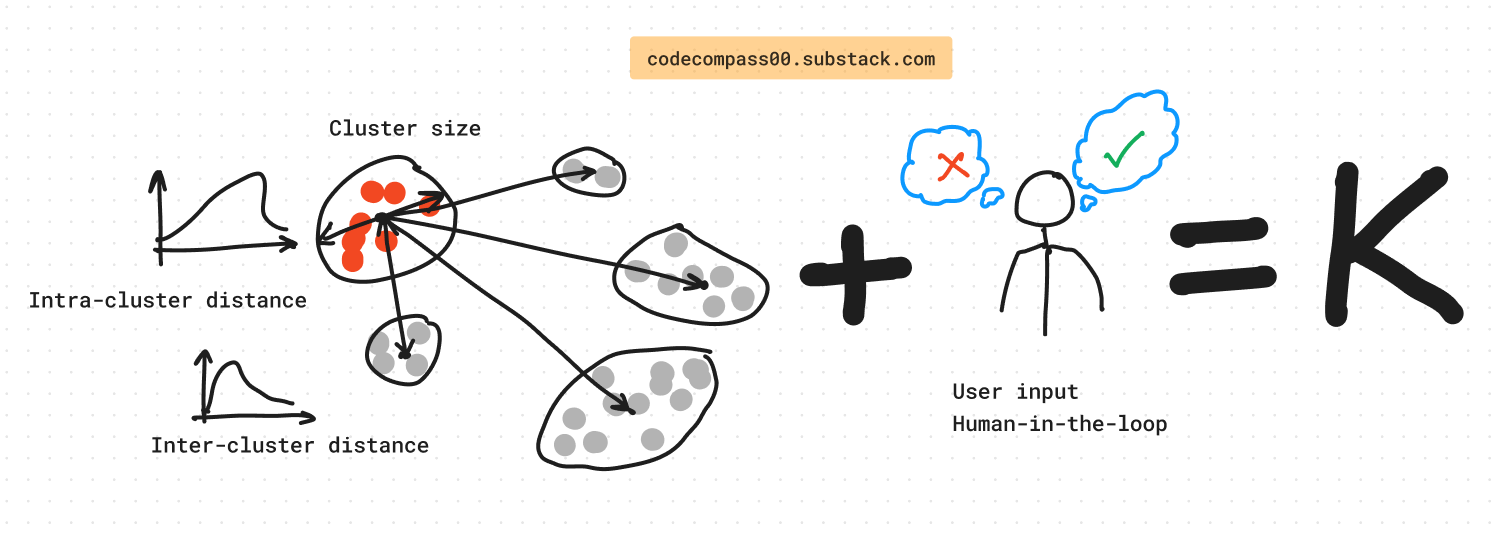
Heuristics to Estimate K: The Number of Identities
During clustering runs, heuristics are used to estimate K, the number of actual identities in the “gallery”. Heuristics based on:
Cluster sizes.
Inter-cluster distances: their distributions and their variances.
Intra-cluster distances: their distributions and their variances.
User inputs as mentioned in the human-in-the-loop discussion above.
This step helps the system assign observations dissimilar from the “gallery” to completely new identities.
6. Assigning An Identity To A New Observation
During deployment, instead of representing a cluster using the mean (centroid) or the median of the cluster, the implementation uses a set of canonical exemplars.
Exemplars are a subset of the cluster that is representative of the contents of the whole cluster. They capture the variability of a cluster much better than having a single item representing it. Keeping a few exemplars avoids the need to store all the points in the cluster and still maintain a rich representation of the cluster.
A pre-deep-learning method called Eigenfaces [2] follows a similar approach.
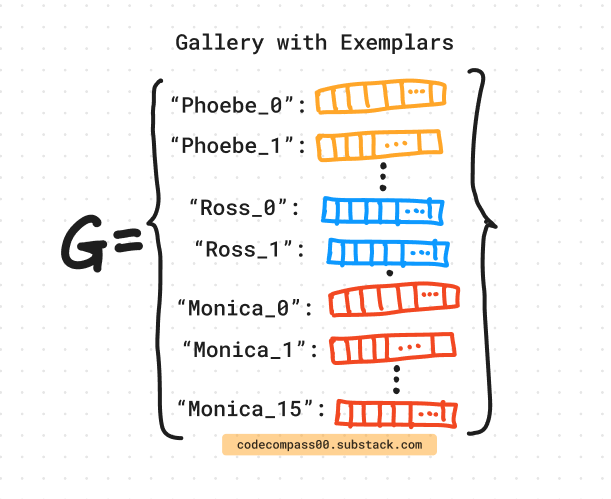
A gallery for K identities has the following structure:
where, N_i are the number of exemplars for the i-th identity.
A new observation X_? comes in. We solve a Lasso-like objective [1] to assign X_? to an identity.
The second term in the objective forces the solution y to have very few non-zero values (= sparse solution), and most of the values are forced to zero (controlled by regularization constant lambda)
X_? is assigned to the cluster whose exemplars have the largest contribution in the sparse vector y.

Sparse coding generates a sparse distribution instead of a single maxima, and is useful when multiple clusters belong to the same identity. It handles cases where the clustering algorithm may split examples of the same identity into multiple clusters due to varying viewpoints, lighting, occlusions, etc. Unlike nearest neighbor, sparse coding allows the sparse code y to have non-zero coefficients across multiple clusters corresponding to the same identity.
7. Gallery Housekeeping
It is important to keep the gallery free of any noisy entries, including false positives of out-of-distribution faces and bodies, to ensure precise matching and clustering.
Detections of Mickey Mouse's face (a fictional character) should not be included in the gallery. Similarly, a false positive such as a blurry blob that looks like a face if you squint your eyes hard. A classifier helps weed out these entries.
After the main model is trained a classifier head is added to predict these out-of-distribution observations. The features from the pre-trained backbone are used to train this head. It is trained on actual faces (positive samples) and random crops (negative samples) and helps filter out incorrect detections.
Apple’s iPhones and iPads run these steps overnight (during phone charging) and recognize you and your friends in newly clicked photographs.
The Devil Is In The Detail
In the sections below, we dive deeper into how Apple’s ML application squeezes performance on a mobile device without ever needing to send your photos outside the phone.
We go over key model architecture choices, how models are benchmarked and improved, model training, and a bit more math-heavy section about loss functions (deep breath, we will go over it one by one).
8. Model Evaluation and Improvement
To improve the model, diverse user personas are added to the dataset using paid crowd-sourcing to curate high-quality data across demographics.
Users take photos with a wide range of styles and content, which makes it challenging to capture subjects of varying age, gender, and skin color. To address this, Apple tests its system across different user groups or personas, using a solid benchmark. The benchmark mimics user personas [6], including their usage patterns and photography styles.
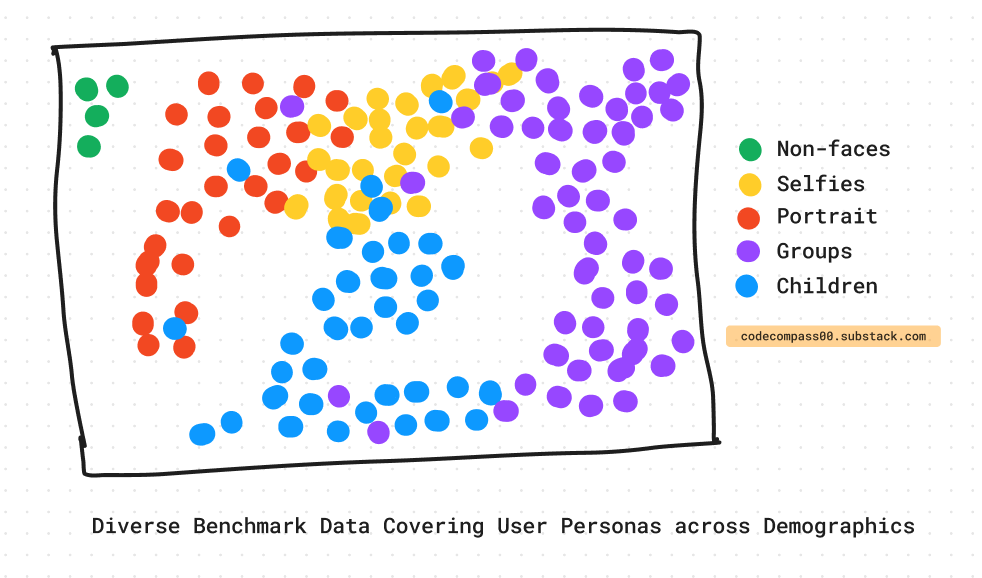
A model's performance on a large, high-quality, and representative benchmark closely approximates real-world performance across demographics.
It is important to consider performance improvements and regressions across demographics when making decisions about the deployed system to avoid rollbacks and loss of customer trust.
9. Model Training
Major boosts in performance are attributed to applying relevant data augmentations. Per-pixel transforms such as brightness, contrast, color jitter, grayscale conversion and structural transforms such as blur, compression, cutout, distortion, and mirroring improve generalization.
The training process starts with simpler transforms and through the training process, more difficult transforms are applied in a curriculum learning-like framework. The parameters are randomly initialized and are optimized using AdamW optimization.
Augmentations and curriculum learning improve performance on the worst and best-performing subsets of their curated dataset. The worst-performing subset performs ~3.7x better and the best-performing subset performs ~1.5x better. More importantly, the gap between these 2 is reduced by ~4.3x.
The training objective is to generate embeddings on a unit-hypersphere i.e. the embeddings or feature vector is unit length (|v_{embedding}| = 1). As the training progresses, similar identities should form clusters along the hyper-sphere radius and dissimilar identities should be pushed away. Since all embeddings are vectors of length one on the hypersphere, distance can be computed using cosine similarity between the unit vectors.

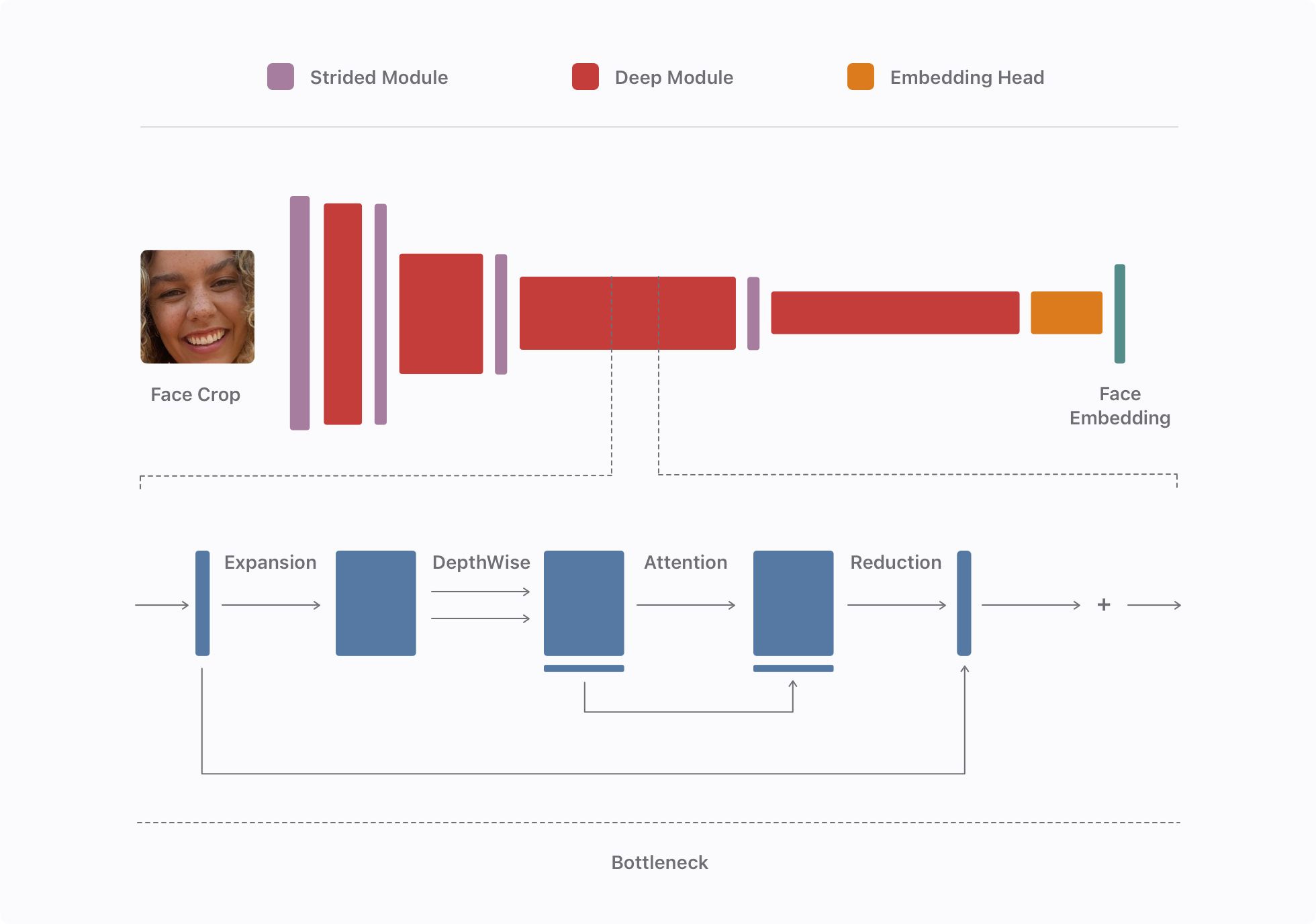
10. Model Architecture
The model is run privately and on-device. A lightweight and efficient model is required for the task. They use a modified version of the model proposed in AirFace [9].
They can increase the depth of the model with the help of bottleneck modules from MobileNetv3 [10] and 1x1 convolutions to expand and contract feature dimensions. Read more about what 1x1 convolutions in a previous post.

They apply channel-wise attention similar to the proposal in Squeeze and Excitation Networks [11].
Finally, the network outputs and embedding using a linear global depth-wise convolution which learns the projection from the second last layer to the final output compared to a vanilla global pooling transform which treats all regions of the feature map equally [12].
11. Training Loss
The goal is to minimize inter-class similarity and maximize intra-class similarity of the embeddings. To this end, a modified version of the softmax is used. The task is to classify a subject correctly and assign them to their corresponding identity.
Traditional softmax can be used but does not explicitly force the embeddings to have small intra-class variance and large inter-class variance. Modifications are made to remedy this.

Here is the contribution to the loss for a single data point x that belongs to the i-th identity has the following contribution to the loss using traditional softmax:
is modified by dropping the bias c and replacing the dot product as follows:
where theta is the angle between w and x.
w_i is one of the vectors in a matrix W which contains K anchor vectors, one for each identity in the training dataset.
w_i and x are normalized to have unit length so
Finally, to force intra-class compactness and inter-class discrepancy, a margin m is added to the term corresponding to the ground-truth label. The margin is reminiscent of the margin in support vector machines (SVMs).
Embeddings of data point x that belongs to the i-th identity has the following contribution to the loss,
Here, theta_i is the angle between the embedding x and the anchor vector of the i-th identity in the matrix W i.e. w_i. theta_j is the angle between x and all the other (non-ground truth) anchors w_j in W where j =/= i.
Finally, a reweighting function f gives more importance to hard samples [13].
Outro
Apple performs on-device ML for person recognition keeping photos on the device. The model is lightweight with a minimal memory and battery footprint. Face and body cues are used to recognize subjects.
To cope with visual variations such as clothing and hairstyle, contrastive learning is used to pre-train a model on a diverse dataset. The model is evaluated and improved using a solid benchmark that captures various user personas. Curriculum learning is used together with data augmentation to provide significant performance boosts. The embeddings are trained using a custom loss function that encourages tighter intra-class clusters and wider inter-class separation.
So the next time you see your phone identify you and your friends, you know what under the hood made that happen!
Interested in reading more? See how Netflix uses ML to predict what content to create:
Consider subscribing to get it straight into your mailbox:
References
[1] Lasso: https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.Lasso.html
[2] Eigenface: https://en.wikipedia.org/wiki/Eigenface
[3] Recognizing People in Photos Through Private On-Device Machine Learning: https://machinelearning.apple.com/research/recognizing-people-photos
[4] Agglometarive Clustering: https://scikit-learn.org/stable/modules/generated/sklearn.cluster.AgglomerativeClustering.html
[6] From PhotoWork to PhotoUse: exploring personal digital photo activities: https://www.tandfonline.com/doi/full/10.1080/0144929X.2017.1288266
[7] A Multi-Task Neural Architecture for On-Device Scene Analysis: https://machinelearning.apple.com/research/on-device-scene-analysis
[8] Fair SA: Sensitivity Analysis for Fairness in Face Recognition: https://arxiv.org/abs/2202.03586
[9] AirFace: Lightweight and Efficient Model for Face Recognition: https://arxiv.org/abs/1907.12256
[10] Searching for MobileNetV3: https://arxiv.org/abs/1905.02244
[11] Squeeze-and-Excitation Networks: https://arxiv.org/abs/1709.01507
[12] MobileFaceNets: Efficient CNNs for Accurate Real-Time Face Verification on Mobile Devices: https://arxiv.org/abs/1804.07573
[13] CurricularFace: Adaptive Curriculum Learning Loss for Deep Face Recognition: https://arxiv.org/abs/2004.00288
[14] Contrastive Representation Learning: https://lilianweng.github.io/posts/2021-05-31-contrastive/
Consider sharing this newsletter with somebody who wants to learn about machine learning:
Here, when we say “model” it is more than just a neural network, it includes preprocessing, postprocessing, and knowledge graphs. Additionally, a database containing information about each recognized identity may be stored on-device as vector DBs.
Training happens off-device for on-device efficiency.
Apologies, there is no inline LaTeX support (yet). :(
Wow! That's an in detail breakdown of the topic. Love this :)