



Creating an AI-Powered Researcher: A Step-by-Step Guide
How to build a system that searches the internet and summarizes, researches and explains the information

One of the most successful "AI wrappers" is the AI knowledge engine Perplexity. It enables users to research and find relevant information, which a Large Language Model then summarizes and explains as an answer to the user's query.
This post will explain how you can create your own AI researcher that finds contextually relevant information from the internet and provides an appropriate answer.
Tech Stack used
There are lots of tools out there, but here’s the tech stack I went with for this blog:
DSPy – An AI framework with built-in prompt optimization. It’s simple, modular, and easy to work with. You can learn more about it here.
Exa – Offers an easy-to-use API to search the web, find relevant info, and pass it along to an LLM.
What do search APIs like Exa do?

Search APIs work by indexing the internet. An easy way to think about them is like retrievers that pull information from web pages and links. What sets them apart is how well they do that indexing. That’s their main “differentiator.” For example, Perplexity API and Exa organize and access web content in different ways.
Below is a simplified version of what Exa’s underlying indexing and search technology does.
Exa is a search engine that combines neural and keyword based search techniques. Instead of relying solely on keyword matching, it uses embeddings, which are vector representations of text, to perform semantic search over its own indexed web content. This allows it to return results that are relevant in meaning even if they don’t contain the exact query terms.
At the core of this is a method called next link prediction, where the model predicts which documents or links are most relevant based on the semantic content of both the query and the indexed documents. This is particularly useful for ambiguous or exploratory queries where users may not know the exact terms to use.
However, for cases where exact matches matter, like proper nouns, technical jargon, or known keywords, Exa also supports traditional keyword search. Both search modes are integrated into a system called Auto Search, which uses a lightweight classifier to decide whether to route the query to the neural search engine, the keyword search engine, or both.
This hybrid setup helps Exa handle a wide range of query types, balancing semantic relevance with precision.
For a more detailed explanation or information you can visit their docs and blog.
We have served 13+ clients, from startups to big multi-national corporations, need help with AI? Press button below
How to use Exa’s API
Now for the fun part on how you can use this API to search contextually relevant information from the web. There are three key methods for the search api
Exa finds the exact content you’re looking for on the web, with three core functionalities:
Search: Find webpages using Exa’s embeddings-based or Google-style keyword search.
from exa_py import Exa
exa = Exa('YOUR_EXA_API_KEY')
results = exa.search_and_contents(
"Find blogs by FireBirdTech",
type ="auto",# can be neural or keyword, based on your preference
numResults=30, # How many results to return
)
print(results)Building a Reliable Text-to-SQL Pipeline: A Step-by-Step Guide pt.1

Many of our clients are asking for text-to-SQL solutions these days, and it’s become a key part of nearly every project we’ve worked on in the last quarter. While it’s easy to get a language model to generate SQL queries, building a reliable system for enterprise use is a different story. For business-critical applications, we need a high…
Content:
Obtain clean, up-to-date, parsed HTML from Exa search results.
from exa_py import Exa
exa = Exa('YOUR_EXA_API_KEY')
#crawls the web for the contents of the webpages specified
results = exa.get_contents(
urls=["https://firebird-technologies.com"],
text=True
)
print(results)
Find similar link
Based on a link, find and return pages that are similar in meaning.
from exa_py import Exa
exa = Exa('YOUR_EXA_API_KEY')
# Find similar links to the link provided and optionally return the contents of # the pages
results = exa.find_similar_and_contents(
url="www.firebird-technologies.com",
text=True
)
print(results)The search feature is simple and easy to use, for a full overview of every feature of the API you can look at Exa’s API reference here
Design of the AI researcher
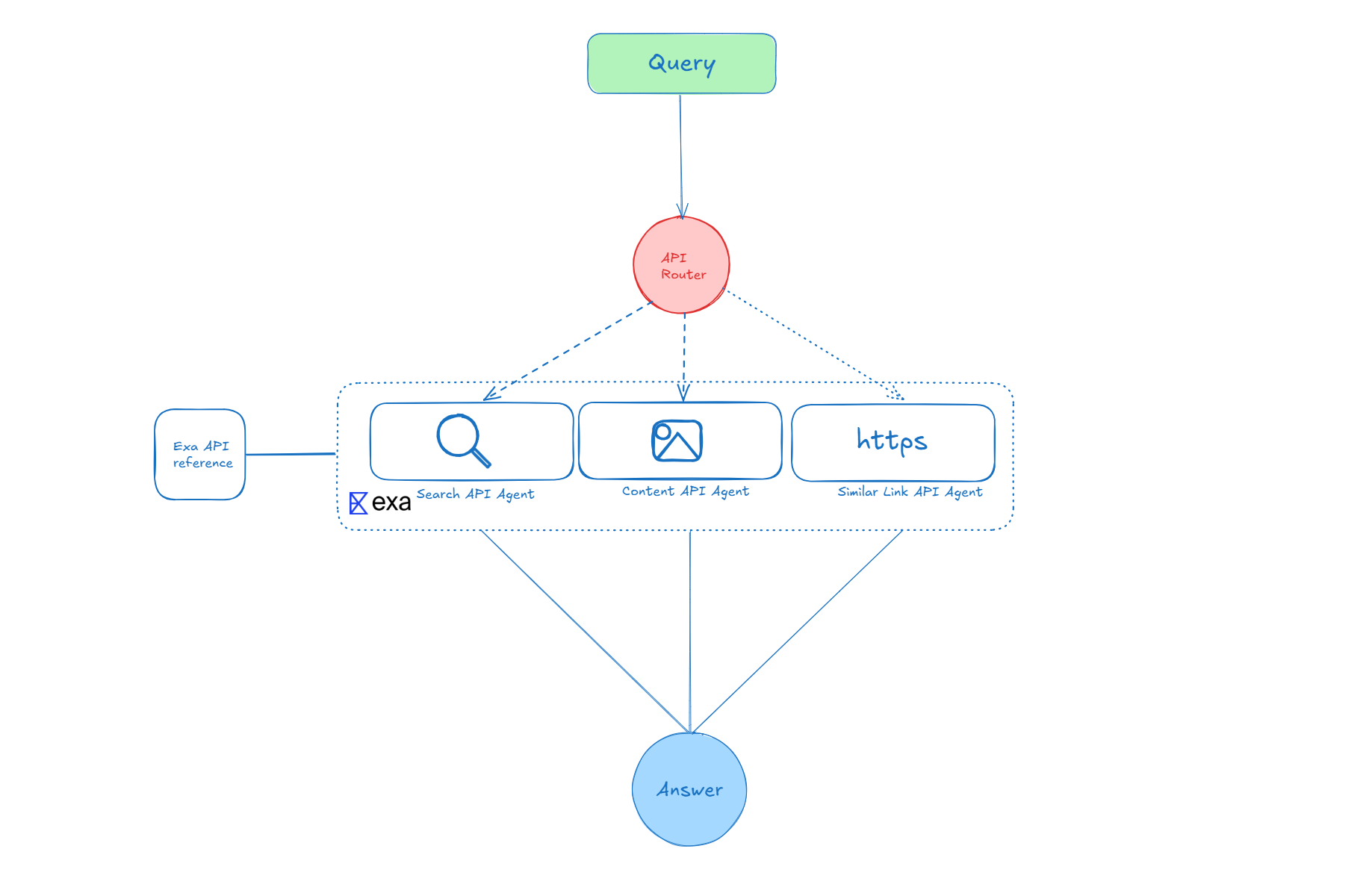
I designed a three-step system so the researcher can use more than one API at a time. Here's how it works:
1. API Router: This part decides which of the three APIs to use for the query. Most queries will only need the search API, but it's helpful to also have the option to fetch content or find similar links.
2. API Agent: There are three agents, and each one is set up with a special prompt that works best with one of the APIs.
3. Answer Layer: This is where everything comes together. The system summarizes and analyzes the information to give a final answer to the user.
Need someone on your team that can develop AI solutions for you? Press button below
API Router
Below is the prompt for the API router
class api_router(dspy.Signature):
"""
You are an intelligent router that decides which Exa API(s) to call to answer a user query. Choose the fewest number of APIs needed to produce a relevant and useful result.
There are three available APIs:
search: Use this to discover new documents based on a topic, keyword, or research question.
contents: Use this when the user provides one or more known URLs and wants full text, summary, or highlights.
findSimilar: Use this when the user gives a URL and wants to find related links.
You can also combine APIs in sequence if needed, but prefer the minimal number of calls.
Return your decision as a list of APIs with a short explanation for each.
Examples:
Query: Summarize this paper: https://arxiv.org/abs/2307.06435
api_selection:contents
selection_reason: Get the summary and highlights of the provided paper.
Query: What are the latest trends in scalable LLM training?
api_selection:search
Query: Find related blog posts to this article: [URL]
api_selection:findSimilar
selection_reason: Find related content based on the URL.
Query: Give me summaries of new papers on few-shot learning
api_selection:search,contents
selection_reason: The user wants summaries of new papers on few-shot learning
Only use findSimilar if a URL is provided and user wants to find related links.
"""
query = dspy.InputField(description="The search query the user wants to search for")
api_selection = dspy.OutputField(description="The API to use for the query - search,content or find_similar_link")
selection_reason = dspy.OutputField(description="The reason for the API selection")
# using chain of thought for better prompting
api_router_agent = dspy.ChainOfThought(api_router)
response = api_router_agent(query = "Find blog posts by FireBirdTech")
Response from the program

API agent
All three API agents have a similar structure, they are feed with Exa’s python documentation.
They have one input (query) and output (API settings)
class search_api_agent(dspy.Signature):
"""
You are an intelligent API assistant that generates structured settings for calling the Exa `/search` endpoint.
Your role is to interpret a user's query and intent, and return a complete Python dictionary representing the JSON payload for the request.
The `/search` endpoint parameters are:
**Basic Parameters**
Here’s the information formatted into a **table** for better clarity:
| **Input Parameters** | **Type** | **Description** | **Default** |
|----------------------------|----------------------------------------------------------------------------------------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------|-----------------|
| `query` | `str` | The input query string. | Required |
| `text` | `Union[TextContentsOptions, Literal[True]]` | If provided, includes the full text of the content in the results. | None |
| `highlights` | `Union[HighlightsContentsOptions, Literal[True]]` | If provided, includes highlights of the content in the results. | None |
| `num_results` | `Optional[int]` | Number of search results to return. | 10 |
| `include_domains` | `Optional[List[str]]` | List of domains to include in the search. | None |
| `exclude_domains` | `Optional[List[str]]` | List of domains to exclude in the search. | None |
| `start_crawl_date` | `Optional[str]` | Results will only include links crawled after this date. | None |
| `end_crawl_date` | `Optional[str]` | Results will only include links crawled before this date. | None |
| `start_published_date` | `Optional[str]` | Results will only include links with a published date after this date. | None |
| `end_published_date` | `Optional[str]` | Results will only include links with a published date before this date. | None |
| `type` | `Optional[str]` | The type of search, either "keyword" or "neural". | "auto" |
| `category` | `Optional[str]` | A data category to focus on when searching (e.g., company, research paper, news, etc.). | None |
---
**Your Task:**
Given a user query and any known preferences (e.g. prefer research papers, want summaries only, exclude news, etc.), generate a JSON-compatible Python dictionary representing the body for a POST request to `/search`.
💡 Example Input:
> Query: "Latest developments in LLM capabilities"
✅ Example Output:
```python
{
"query": "Latest developments in LLM capabilities",
"type": "auto",
"category": "research paper",
"numResults": 25,
"contents": {
"text": True,
"summary": True,
"highlights": False,
"livecrawl": "fallback",
"livecrawlTimeout": 10000,
"subpages": 0,
"extras": {
"links": 0,
"imageLinks": 0
}
}
}
Unless specified otherwise, always keep summary True
"""
query = dspy.InputField(description="The search query the user wants to search for")
api_settings = dspy.OutputField(description="The settings for the search API in python dictionary format")
# ChainOfThought prompting for better responses
search_api_AI = dspy.ChainOfThought(search_api_agent)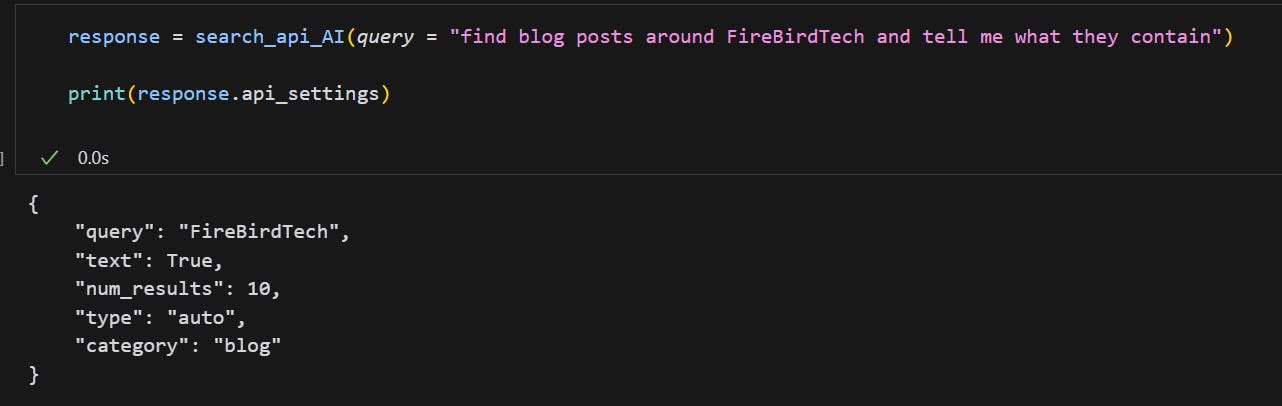
The other two are constructed the same way, with the only difference being the API documentation used.
Answer Agent
class answer_summarize_analyze(dspy.Signature):
"""
### 🔧 **Prompt for an AI Research Agent**:
You are a research assistant AI. Your task is to read through a list of website content and generate a helpful summary based on a user query.
### User Query:
{query}
### Source Data:
{web_data}
---
Instructions:
- Analyze all the web_data provided.
- Focus only on content relevant to the query.
- Provide a concise and informative summary of the findings.
- Group or list items clearly if multiple blog posts or sources are referenced.
- Do not include unrelated metadata (like ratings, loading GIFs, etc.).
- Provide links to the original posts when helpful.
- Be accurate, neutral, and professional in tone.
Respond only with the analysis, summarise and answer to the user query!
---
### 👇 Example with your provided input:
**Query:**
> Find blog posts around FireBirdTech and tell me what they contain.
**Resulting AI Response:**
Here are some recent blog posts related to FireBirdTech:
1. **[Jaybird 5.0.5 Released](https://www.firebirdnews.org/jaybird-5-0-5-released/)**
A new version of the Jaybird JDBC driver introduces bug fixes and minor feature enhancements:
- Fixed precision issues for `NUMERIC` and `DECIMAL` columns.
- Improved support for auto-increment columns and metadata queries.
- Added support for Firebird 5.0 features and updated Java compatibility.
2. **[Firebird Monitor Tool – Version 2](https://www.firebirdnews.org/real-time-firebird-monitor-for-firebird-server-2-5-3-0-4-0-5-0-2/)**
A real-time database monitoring tool with trace and audit capabilities. A 10% discount is offered until June 2024.
3. **[Database Workbench 6.5.0 Released](https://www.firebirdnews.org/database-workbench-6-5-0-released/)**
New features include Firebird 5, MySQL 8.3, and PostgreSQL 16 support. A new SQLite module has been introduced for enhanced compatibility.
4. **[DBD::Firebird Perl Extension v1.38](https://www.firebirdnews.org/perl-extension-dbdfirebird-version-1-38-is-released/)**
Updates include support for Firebird’s BOOLEAN data type and improvements to compatibility with older Perl and Firebird versions.
5. **[Kotlin Multiplatform Firebird SQL Client Library](https://www.firebirdnews.org/firebird-sql-client-library-for-kotlin-multiplatform/)**
A client library for accessing Firebird databases from Kotlin Multiplatform environments, targeting JVM, Android, and native.
6. **[IBProvider v5.37 Released](https://www.firebirdnews.org/release-of-ibprovider-v5-37/)**
A Firebird database provider for C++ with updates including improved error message handling, ICU changes, and thread pool improvements.
7. **[Firebird Export Tool](https://www.firebirdnews.org/firebird-export/)**
Open-source tool to export Firebird databases to formats like CSV and JSON, supporting selective exports and blob data.
8. **[RedExpert 2024.04 Released](https://www.firebirdnews.org/redexpert-2024-04-has-been-released/)**
A new version of the RedExpert tool for managing and developing Firebird databases.
9. **[libpthread Compatibility Warning for Firebird 2.5](https://www.firebirdnews.org/libpthread-compatibility-problem-with-firebird-2-5/)**
Compatibility issues have been found between newer libpthread versions and Firebird 2.5 on Linux. Patching or upgrading is recommended.
10. **[Hopper Debugger v2.3 Released](https://www.firebirdnews.org/stored-routine-debugger-hopper-v2-3-released/)**
A debugging tool for stored routines with new Firebird 5 support and general bug fixes.
"""
query = dspy.InputField(description="The query that the user wants to get the contents of")
web_data = dspy.InputField(description="The web data that the user wants to get the contents of")
answer = dspy.OutputField(description="The answer to the user query")
answer_summarize_analyze = dspy.ChainOfThought(answer_summarize_analyze)
response = answer_summarize_analyze(query = "find blog posts around FireBirdTech and tell me what they contain", web_data = result.results[1].text)
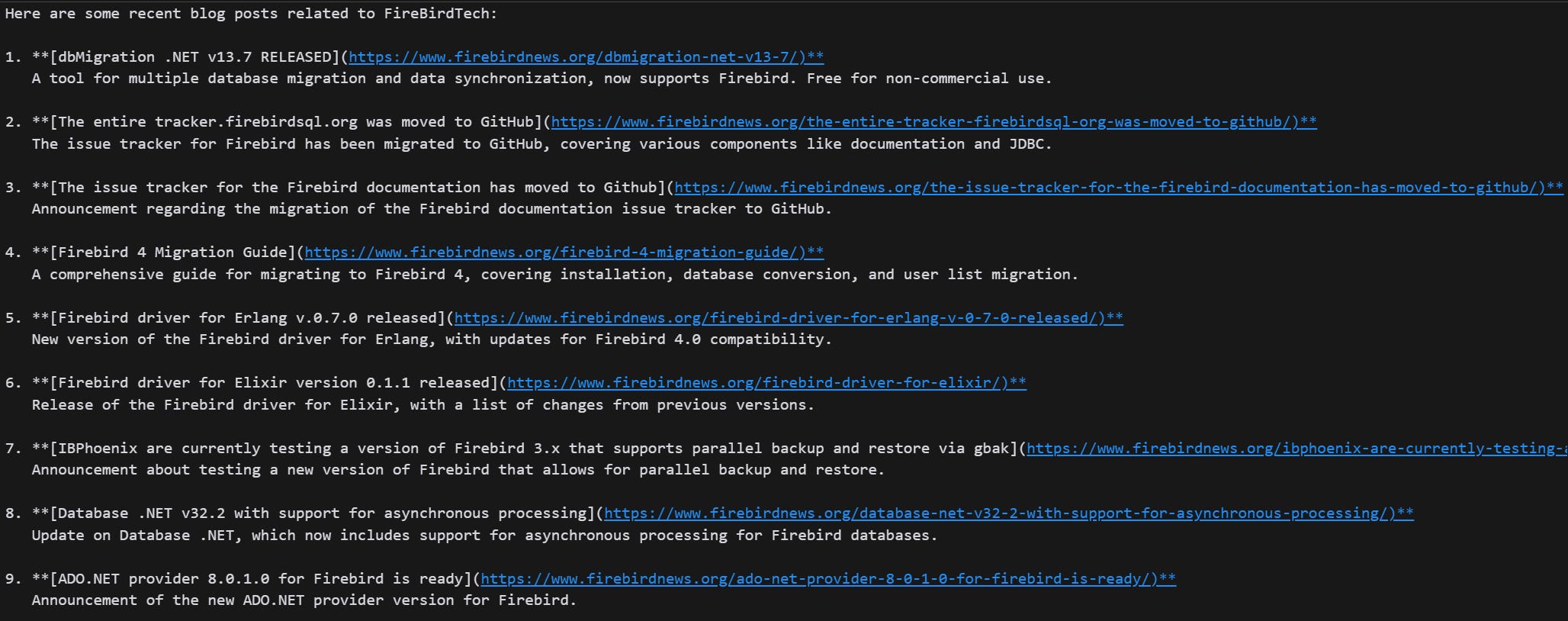

Combining all components
Now we just to combine everything into one system to answer user queries.
class research_agent(dspy.Module):
"""A research agent that routes queries to appropriate APIs and returns analyzed results"""
def __init__(self):
# Initialize API components
self.api_router = api_router_agent # Routes queries to appropriate APIs
self.search_api = search_api_AI # Handles search API calls
self.contents_api = content_api_AI # Handles content API calls
self.find_similar_api = find_similar_api_AI # Handles similarity search
self.answer_summarize_analyze = answer_summarize_analyze # Analyzes results
def forward(self, query):
"""
Process a query through appropriate APIs and return analyzed results
Args:
query (str): The user's research query
Returns:
str: Analyzed and summarized answer based on API results
"""
# Route query to determine which APIs to use
route = self.api_router(query=query)
api_result = []
# Process query through each selected API
for api_selection in route.api_selection.split(','):
print(api_selection)
if "search" in api_selection:
# Handle search API
api_settings = self.search_api(query=query)
# Convert API settings string to dict
api_settings = api_settings.api_settings
api_settings = json.loads(api_settings.replace("'", '"').replace("True", "true").replace("False", "false"))
print(api_settings)
api_result.append(exa.search_and_contents(**api_settings))
elif "contents" in api_selection:
# Handle contents API
api_settings = self.contents_api(query=query)
api_settings = api_settings.api_settings
api_settings = json.loads(api_settings.replace("'", '"').replace("True", "true").replace("False", "false"))
print(api_settings)
api_result.append(exa.get_contents(**api_settings))
elif "findSimilar" in api_selection:
# Handle similarity search API
api_settings = self.find_similar_api(query=query)
api_settings = api_settings.api_settings
api_settings = json.loads(api_settings.replace("'", '"').replace("True", "true").replace("False", "false"))
print(api_settings)
api_result.append(exa.find_similar(**api_settings))
# Collect and analyze results
answers = []
for result in api_result:
answers.append(result)
# Generate final analyzed answer
answer = self.answer_summarize_analyze(query=query, web_data = str(answers))
return answer.answer
researcher = research_agent()
result = researcher(query="How is Tesla's stock doing since 2020, get me new articles and press release links")
Here is an example of the system using similar link API
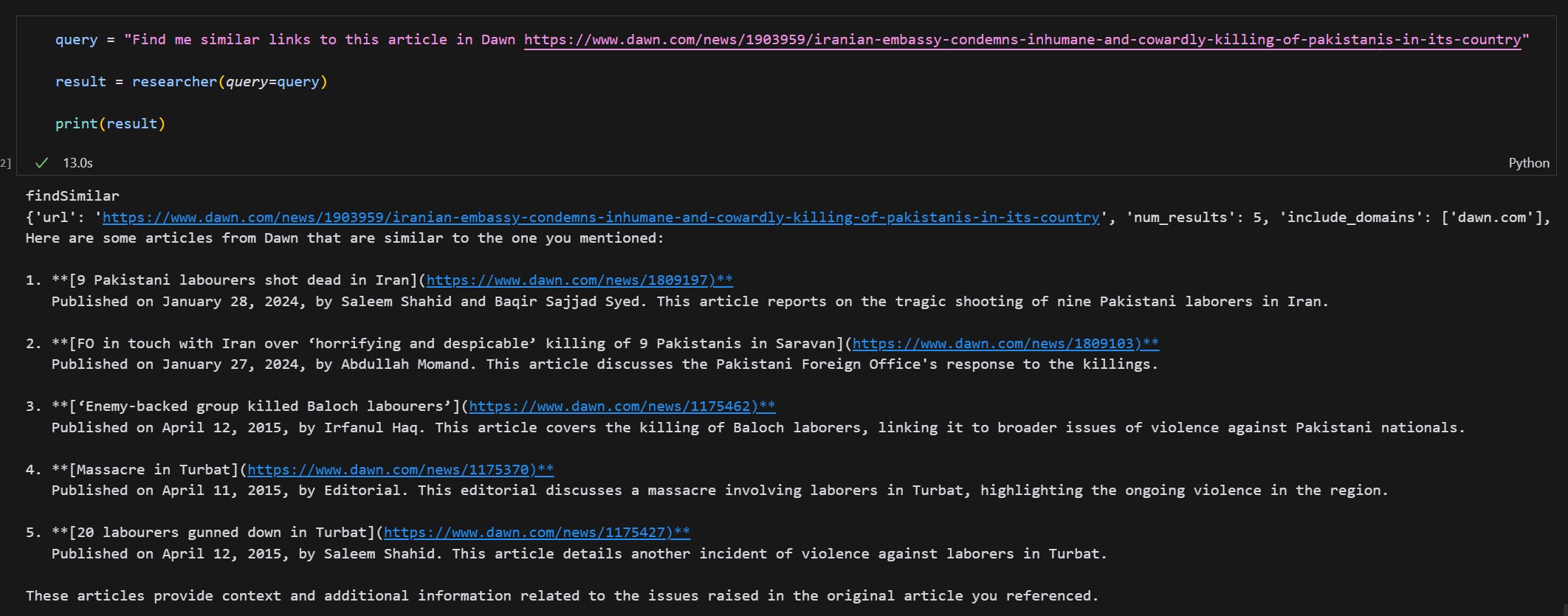
Thank you for reading! As a follow-on the project, I will be adding a ‘deep research’ feature into this system.
Please follow us on Linkedin, Medium and substack