

Storage-Facilities Architecture
Storage-Facilities Architecture
A plea for mature industry.

An attempt to delineate a general solution for typical problems appertain to web software development. If you browsed the source code of any open-source web application, fully developed using JavaScript in particular, you would probably find that its architecture is brutally shaped by a framework or, even worse, by a library (there are tools proclaimed as libraries, but they are usually used as frameworks in the sense that they specify at least one part of the architecture). Developing a large software project bounded to a specific framework is a pernicious decision which is significantly what led to the wide range of irrelevant, to the art of software development, titles: React Developer, VueJS Developer, ExpressJS Developer, ...etc (“Software Developer” or even “JavaScript Developer” should be sufficient). This article prescribes a general architecture, perceived as a receptacle box in which various frameworks can be plugged, that web developers can implement regardless of what technology will be used in the future.
This article is a plea for mature industry!
The article is also available in PDF.
You may also check out GlobalStore which is an application of the architecture.
1. Introduction
Any program can be considered as a store with one or more storage and at least one facility for each storage. Any subprogram, moreover, is a program itself; hath its own storage and facilities (a program can relatively be called storage or facility for another). Storage can vary in properties: such as structures and types of elements. However, they can share facilities. A facility is an equipment that is used to retrieve, manipulate, or remove elements from storage. Speaking more technically, a program is an accumulation of algorithms and data structures, as the store is a collection of facilities and storage. This is the perception upon which each piece of the architecture will be designed.
To amplify the distinction between storage and facilities in more technical sense, we shall define a storage as a subprogram, a set of classes, or a set of types (structures or interfaces), whereas a facility is either a subprogram or a set of classes. A storage can be a subprogram in case it has high level of complexity which requires breaking it down, it can be classes whose methods will be delegated by facilities, or it can be just types that will be used by facilities. Similarly, a facility can be a subprogram, or classes that will either use the types of the storage, delegate some functionality to the classes thereof, or merely use other facilities. Furthermore, Facilities can be classified by their usage level of the storage; the more a facility uses storage elements, the lower it gets in level.
In most cases, a storage is probably a set of types; so, conveniently, the word “storage”, with neither “subprogram” nor “class” adjective, is straitened to mean only a set of types. Similarly, a facility refers to a set of classes unless it is specified as a “subprogram”.
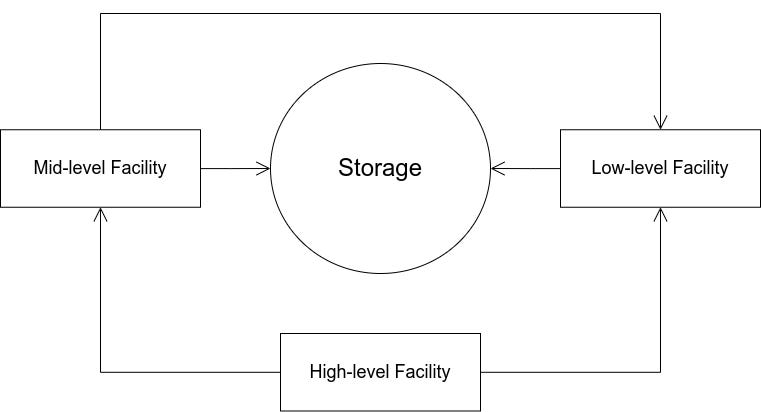
The architecture model may be visualized in different ways, however, flatting approach is preferred as it’s relatively straightforward and simple, compared with tree approach and segregated storage approach (these two are not elaborated as they are not used, however, one can easily conceive them considering the names).
Flatting Approach doesn’t distinguish between subprograms components (storage and facilities) and the main program components. It includes all different storage elements in the middle, and surrounds them with all facilities, as illustrated in figure 1. For instance, if X is a program with S0 as its storage and Y and Z as its facilities, whereas Y is a subprogram facility that contains a storage S1 and a facility F. Then, the model of program X can be visualized, by flatting approach, as only one storage: the union of S0 and S1, surrounded by two facilities: F and Z — Y is omitted.
In other words, Flatting Approach expressively excludes subprograms and includes only classes and types compacted in one storage and many facilities.
2. Backend
This component (the backend) is considered as the storage of the web application. It has only one storage along with its facility, which we shall call the "Database" and the "Server", respectively. Each of which, in turn, contains its own storage and facilities.
The Database
The Database represents the overall concept behind the system; as it should be only coupled to the business rules. It has one storage with two facilities; the storage is merely a set of data types or structures that specify the properties of data units to be stored, whereas the facilities are DataController and QueryManager.
DataController is a low-level facility that shall use each type of the storage to create, update, remove, and retrieve data. On the other hand, QueryManager is a high-level facility in the sense that it uses DataContoller, and it provides a framework that users shall use, rather than directly using DataControllers, to set the required queries (DataController methods) in a chain and execute them sequentially.
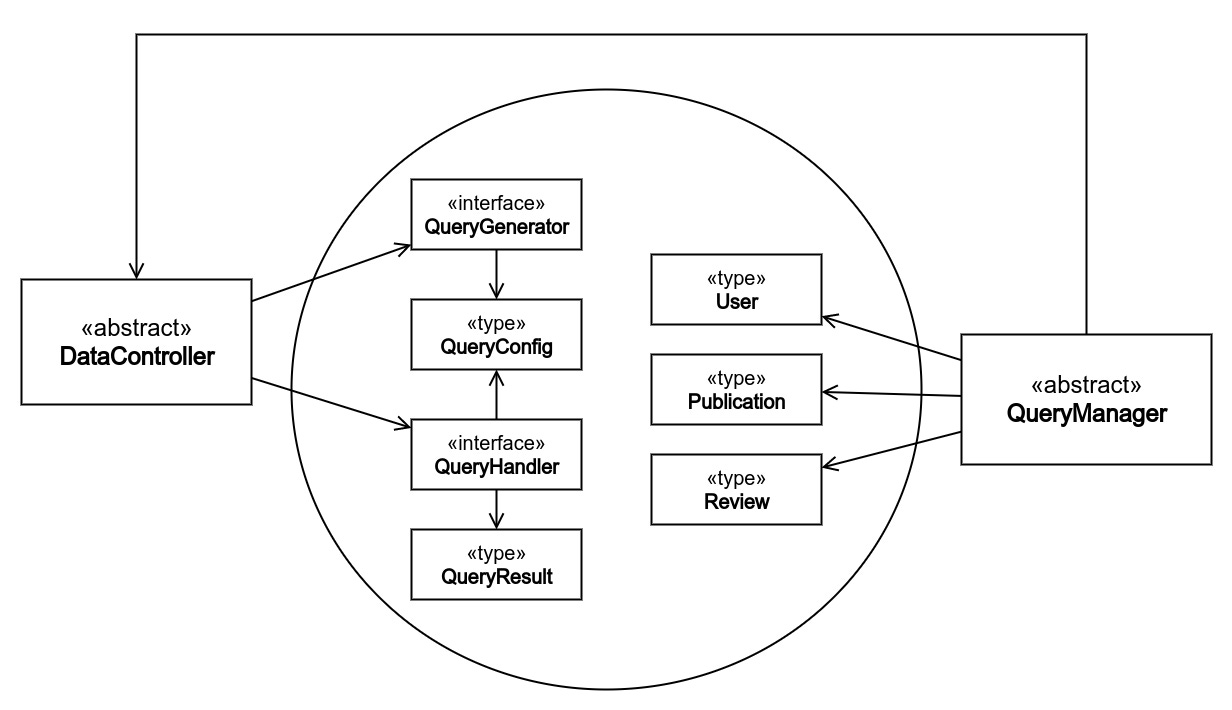
DataController
DataController is a subprogram with a type storage and class facility. To define a DataController, first we need to specify four underlying types:
QueryGenerator,
QueryConfig,
QueryHandler,
and QueryResult.
QueryGenerator is an interface declares a set of methods each of which generates a distinct QueryConfig. Whereas a QueryConfig is a structure that specifies precisely a use case in a way that QueryHandler can interpret. A QueryHandler, in turn, is a class with at least one method which takes QueryConfig as input and produces QueryResult as output. Last but not least, QueryResult is a data type specifies the value that the user expect to get from queries.
Second, we shall define a class that uses the four types and employ them together to send queries more handily. It encapsulates the use of the storage (the four types), and provides users with a set of expressive methods, relieving the burden of knowing about the four types, that they should use rather than tediously employing the four types in order to accomplish a simple query.
QueryManager
QueryManager is a class facility that specifies the required DataControllers for the user, by integrating the structures from Database storage (User, Publication, Review, or whatever data structure specified by the business rules) with DataController, along with methods to push queries in a queue, to execute them sequentially, and to retrieve queries results saved so far.
Pushing queries in a queue, then executing them all in order, can have many avails. In case we are using a SQL database, for instance, this would be significant to have; as it defines two points of time in which a connection can be established and terminated. A connection can be established after pushing the first query and can be terminated after the invocation of the last one. It also further the readability of the code;
by writing it in the following form:
QueryManager.query(UserController.get("userid"))
rather than a bunch of lines before and after the query to establish connection, initialize QueryHandler and DataControllers,…etc. Lastly, one of the major features of this approach is that the results of queries can be saved in a stack which may be used ultimately to construct a convenient payload to be submitted to the user.
To save and retrieve queries results, we might simply define an array in this class and use it directly, or more elegantly we may define an inner class called CarrierStack. It has methods to store and retrieve elements, and to reset the stack. It behaves like a stack in storing elements; this is reckoned to be convenient as the last saved query result is likely to be the most required in the payload (assuming the index to be zero, while constructing the payload, will relieve the burden of specifying the index). However, it behaves like an array in retrieving elements, so the user can use the desired result directly without popping the above results.
The Server
As mentioned before, the server is the facility of the backend. And it is a subprogram with a set of types representing its storage along with a set of classes which shall, by using the types, establish together an HTTP server.
Essentially, there should exist an app that involves a set of routers. Each router defines a distinct set of endpoints. Whereas each endpoint defines a path, where the user can send requests, and defines the type of the accepted requests. Moreover each request is handled and a response is sent by a handler. A type, a structure, or an interface shall be defined for each aforementioned item (the italicized words) — all together constitute the storage of the server.
Speaking with a little bit less level of abstraction, an app object is responsible of adding routers and starting and closing the server; app.use, app.listen and app.close methods shall get implemented by concrete objects. The app.use(path, router) method specifies a path and associates it to a specific router object, after using the required set of routers and associate each one to a specific path, the app.litsen(port, host) method shall be called to run the server process on the specified port, and afterward app.close() could be used to kill the process. A router object is responsible for defining a set of endpoints, each of which is associated with a handler, by router.define(endpoint, handler) method. A specific handler is usually used for all endpoints of a corresponding router, the router and the handler, in this case, are called "fully compatible". An endpoint is just a structure with three attributes; the first is a function whereby users can construct a proper path while making requests, the other two are merely strings, one of them indicates the endpoint path for router.define method, while the another indicates the type of the accepted request by the corresponding endpoint. A handler object is responsible for sending responses to users, by different methods for different sorts of responses, after handling their requests by handler.handle method. The handler.handle(request) method either directly sends an error response of "Bad Request", or indirectly sends a response according to the request payload by invoking another local method of the handler; it sends, directly, the error response in case the request body has no “request_name” attribute or there is no local method with the same name as the request, otherwise it invokes the corresponding local method and delegates to it the responsibility of sending the response.
On the other hand, there are only three classes each of which represents a facility. The lowest-level of them is called QueryStrategy which depends on the QueryManager from the database and the Response type of the storage described above. Comes in the second place the RouterInitializer, it's considered as a middle-level facility, and it uses the Handler, the Endpoint, and the Router from the storage. Lastly, the Server is the high-level facility that uses the RouterInitializer and the ServerApp from the storage. We may distinguish between the facility of the backend and the facility of the server itself, by calling the former "server-subprogram" or "the subprogram server" and the latter "server-class" or "the class server".
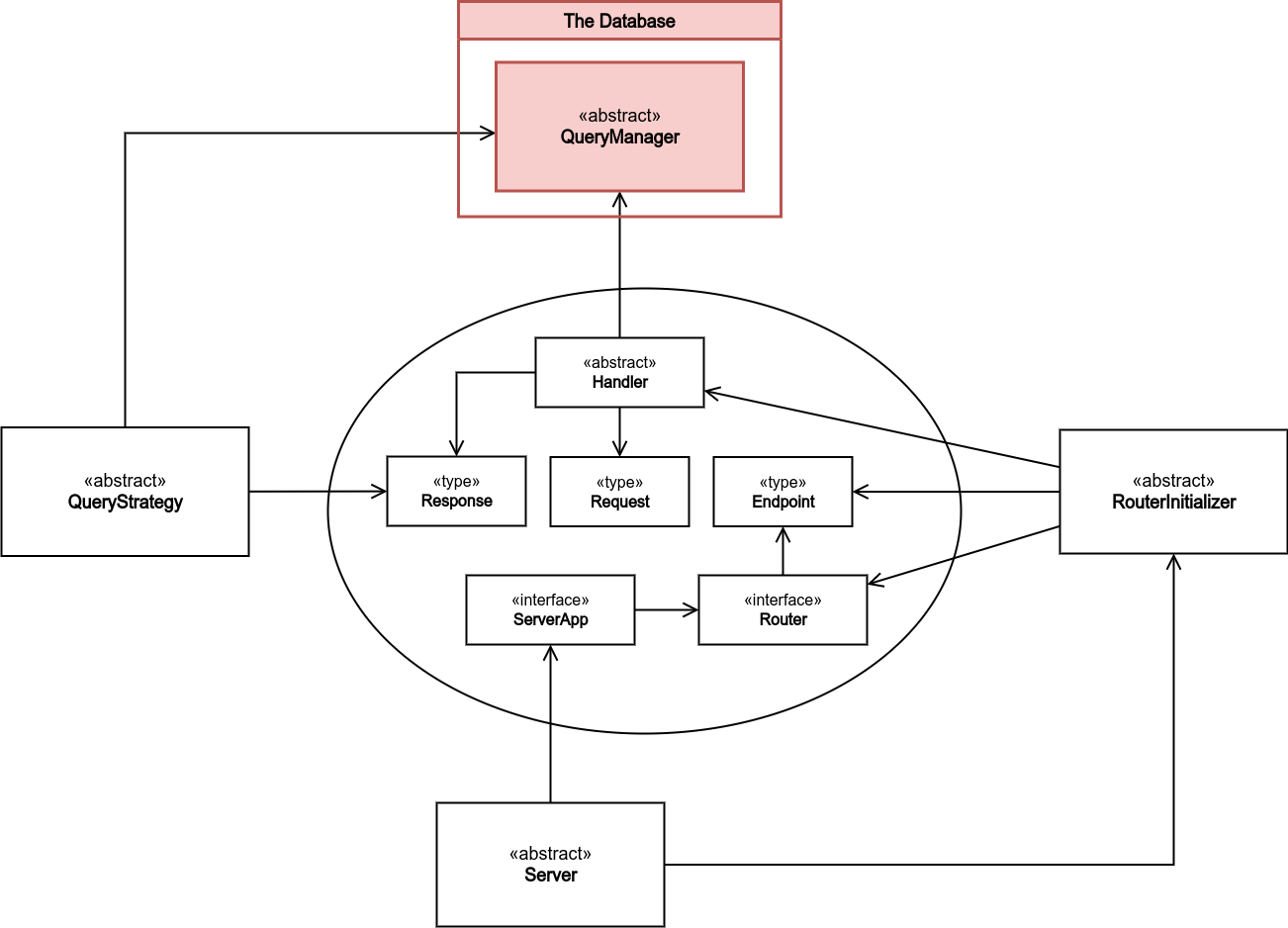
QueryStrategy
This class facility is what connects the backend facility "the server" with the storage "the database". It's ought to be used by concrete handler classes in defining their methods; the handler shall delegate the use of QueryManager and DataControllers to QueryStrategy.
The diagram (Figure 3) shows no dependency between Handler and QueryStrategy, as the dependency may only exist between the concrete objects; QueryStrategy is dispensable.
Each QueryStrategy method should produce a value that's acceptable by the QueryManager.query method as its parameter value. Moreover, each method produces a value that applies, conceptually, either "Retrieve Strategy", "Check Strategy", "Action Strategy", or "Response Strategy".
A function does apply a retrieve strategy if it only retrieves data from the database, by using DataControllers, and returns the value of the retrieved data. In case of an action strategy, the function adds, updates, or removes values from the database and returns nothing. In the remaining two strategies the function, usually, doesn't return values, and it uses the CarrierStack of the QueryManager. The CarrierStack is used in check strategies to get access to the output of the last applied retrieve strategy in order to apply a certain test (condition), which if failed (is false) the function shall throw an error that QueryManager.execute method catches and therefore terminates execution. On the other hand, a response strategy function uses the CarrierStack to construct a payload, then it either returns it or sends it with handler.send method.
QueryStrategy.builder()
Despite the fact that, no much has been said about various objects of this component, the implementation of builder method cannot be overlooked and it worth elaborating.
Typically, using QueryStrategy along with QueryManager in Handler methods shall be in the following code style:
QueryManager
.query(QueryStrategy.retrieveQuery())
.query(QueryStrategy.checkQuery())
.query(QueryStrategy.actionQuery())
.query(QueryStrategy.send(callback))
.execute()QueryStrategy generates some often used composition of (DataController) statements within function block, then passes it to QueryManager which is responsible for executing them in some systematic manner. However, this is not all what QueryStrategy does; as you may have noticed in the last query call, it's also responsible for creating the response payload object for server endpoints. And invoking the callback with the payload as its first parameter value.
QueryStrategy.send method puts the last query result, returned from the other strategy methods, in the payload object — in “data” attribute. In addition, it provides another parameter in order to give more liberty for users to choose which query returned value would be loaded in the response object (any returned result before the last one).
Example:
QueryManager
.query(userStrategy.getById("us1234"))
.query(userStrategy.ifExists())
.query(userStrategy.send(handler.send))
.execute()
Response: {
code: 200,
message: "query fulfilled.",
data: {
id: "us1234",
username: "user1",
…
}
}In some cases, more complex payload structure may be required; and here the role of builder method comes in.
For instance, if you want to get a specific review data with the user (reviewer) info attached to it in the response object, you shall use the builder to build up the response object. This scenario could be implemented as follows:
QueryManager
//4 .query(user.getById(reqparams.userid))
//3 .query(user.ifExists())
//2 .query(review.getFilteredList({
publication_id: reqparams.pubid,
user_id: reqparams.userid
}))
//1 .query(review.ifExists())
//0 .query(review.builder().getListItem(0))
.query(review.builder().define("user", 4))
.query(review.send(handler.send))
.execute()
.catch(e => next(e));
Response: {
code: 200,
message: "query fulfilled.",
data: {
title: “Gorgeous!”,
…
user: {
id: "us1234",
…
}
}
}builer().getListItem(index) just re-return the last returned value or the first element of the last returned list, from a strategy-query-method. While builder().define(string, index) defines a new attribute in the last created (returned) object from the builder, and assigns a specified strategy-query-method returned value to it using an index (its second parameter).
RouterInitializer
Typically, the user shall create one app and define along with it a few number of routers. This process could be effortless, however, specifying each single endpoint of each router, and furthermore handling each endpoint request with a handler, before passing it (the router) to the app makes the process extremely tedious. Hence, the responsibility of initializing the router is considered to fall upon this facility class.
RouterInitializer is an abstract class that contains the required attributes and mechanisms for initializing the router. The concrete classes of RouterInitializer shall only implement RouterIntializer.init method which is reckoned to be just a bulk of endpoint define statements. For instance:
class UserRouterInitializer extends RouterInitializer {
method init {
this.define(endpoint);
…
}
}Whereas, RouterInitializer.define method is implemented in the abstract class; it uses the router and the handler attributes (which get defined by the constructor) in order to define the passed endpoint parameter.
class RouterInitializer {
method define(endpoint: Endpoint) {
this.router.define(
endpoint,
this.handler
);
}
}In addition, a router name attribute shall be defined in the constructor, as it’s required by the app.use(routername, router) method.
Lastly, the used endpoints can be explicitly specified in RouterInitializer.init method implementations, it can be stored in and used from an external file, like JSON file, or it can be classified and used through an EndpointsCollection class. The last two ways are preferred over the first, as they will definitely improve RouterInitializers quality by segregating the specification of endpoints from it. And it allows us to taxonomize different endpoints by the used technology and the corresponding router (for instance, ExpressUserEndpointsCollection).
Server-Class
This abstract class represents the highest-level facility of the server-subprogram; it only uses the app from the storage and the already stated facility: RouterInitializer.
The server-class facility is responsible for starting, as well as closing, the server, and before that initiating it by specifying the host, the port, and the used routers. It can be considered as a surrogate for app. However, in terms of storage-facilities architecture terminology, we would probably describe it as a facility that bestows users access to, and/or use of, the storage or more specifically the app methods: app.listen, app.close and app.use.
A server-class class has four attributes and three methods. The attributes are app object, host address, port number, and list of RouterInitializers. And the methods are server.start, server.close, and server.addRouter. The app, host, and port values are specified, and given by the user, in the constructor. While methods merely delegate the functionality to the app; start method first loads the routers by using app.use and the list of RouterInitializers then it starts the server by invoking app.listen, close method just invokes app.close, and addRouter method adds a RouterInitializer object to the list.
Concrete server-class implementations will probably override the constructor and the start method. The constructor could be overridden in order to let the user specify the host and the port, whereas the app is specified statically using any convenient concrete app object. On the other hand, the start method may be overridden to add routers statically rather than bothering the user with creating and adding them, or even to make any technology-specific initiation before invoking app.listen.
3. Frontend
Three straightforward issues ought to take all of our concern while developing the frontend. The first is about the UI; we need to provide a well-organized and sophisticated tool that can deal, eligibly, with drawing different UI views for the user. The second is about state management; where the whole application data is stored, and different data-related mechanisms are marshaled. The third is about Server Communications; the bridge that makes it possible for the frontend to communicate with the backend in a comprehensive and flexible manner.
In the following sections, we shall describe and specify these three design components: UIPainter, StateManager, and RequestDispatcher; which are going to solve the three issues mentioned above, respectively.
StateManager can be considered as the storage of the frontend, whilst the UIPainter and RequestDispatcher are reading and writing facilities.
StateManager
StateManager takes the full responsibility to store various application data, and to provide its access and update facilities. This component ought to be the most stable among the others, and as abstract as possible; it considered to carry out the business rules: it must not depend on other components and must define a general reusable design that can implement the business rules and cope to their future changes.
Generally, storing and manipulating any kind of data requires defining two objects; one describes the structure of the data units, and the other defines the features — the methods that could be applied to the data. We shall give the both names: Entity and Controller.
Where a state is defined as a set of entities with a common controller, a StateManager requires an additional object to manage this entities-controller environment; it delegates retrieval and manipulation functions to the controller, and it's also responsible for creating/storing entities and adding, removing, and invoking update callbacks. However, in implementation, StateManagers could be called states, more like genus and species. For instance, a UserListState object doesn’t just represent a set of entries along with their controller, it may also define the methods used to manage this environment; it may invoke update callbacks.
While Entity, Controller, and AppState constitute the storage of this component, it has three facilities: SingleState, ListState, and StateFactory. Which will be described in the following sections.
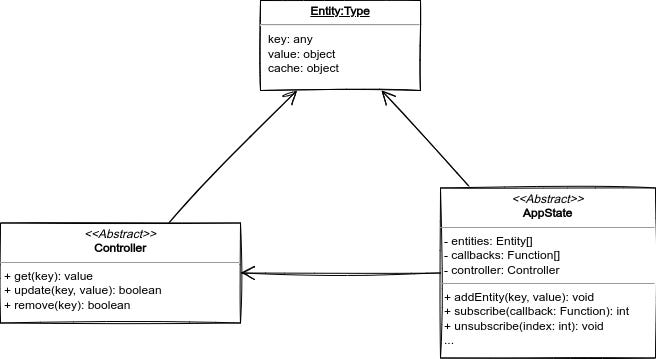
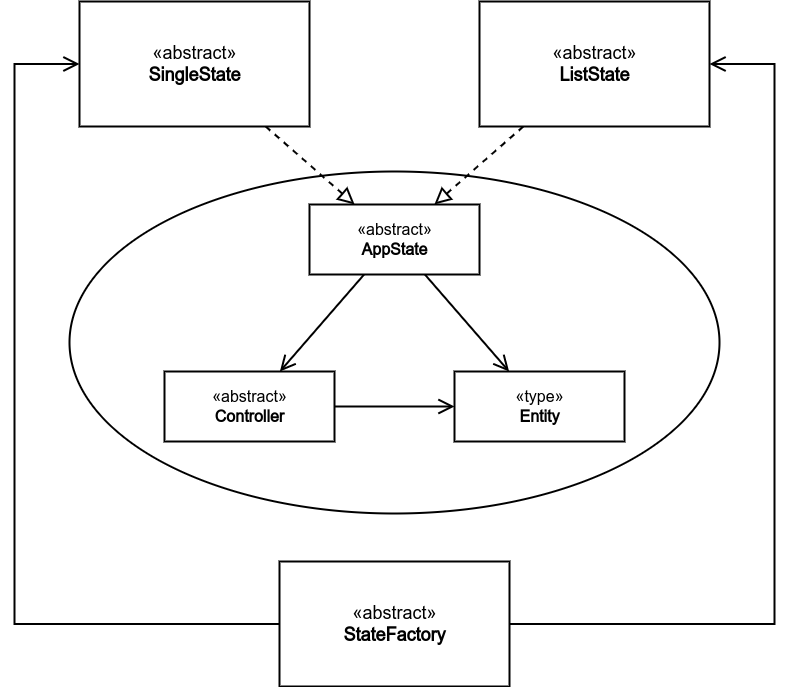
Entity
It's just an object with three attributes: one of them is a unique key which identifies a specific unit of data, another is a cache value which could be used by the controller to avoid unnecessary overhead computations if possible, and finally the third is the value to be stored which could be of any type (it even could be another State/StateManager).
The cache could be used, for instance, to decide whether to update a big list of publications or not, one naive way to do that is by comparing the length of the list with the number of current publications retrieved from the database. Moreover, the generality in the Entity value attribute gives StateManagers a nesting property; whereas each StateManager could contain more than one Entity in which another StateManager is stored.
Controller
A Controller manipulates Entities that's associated to the same StateManager. It must not care about any thing rather than manipulating the entity value; it must not know about update callbacks or cache values. It only knows, at least, how to read, update, and remove the Entity value attribute.
Reading the value could simply be returning it, parsing it as a string or JSON, or even reconstruct it to a specific more complex form then returning it. Updating the value should replace the entire value attribute with a new object adhering the structure in the specified Entity object. Removing the value is just replacing it with NULL (or an object with no values assigned to its attributes).
AppState
A state is defined by a set of entities and a controller that's compatible with the structure of the entities. However, a state object is responsible to invoke the controller methods in order to manipulate the entities, and to store, remove, and invoke callbacks, as well.
In addition, it should give the user a method to get the state (the set of entities) compiled into one JSON object with the proper values been evaluated; if one of the entities is just another StateManager, then it must be compiled in turn as well. Similarly, it shall provide a method for loading the state(s) from a JSON object.
The Triad in Ground
Finally, in this section we are going to see how the triad: Entity, Controller, and AppState, can be employed together, in harmony, to develop a StateManager that's suitable for almost any software application. First of all, we'll define the RootState which we may call the "TRUE" StateManager (among all of these AppStates/StateManagers). Then, we shall define general types of states, from which all the required states in the application can be derived, to be used by the Root. And last but not least, a factory class may be added to improve the quality of the code: the StateFactory is responsible for generating and customizing derived states, from the general ones (SingleState & ListState), by using different structures (data unit objects) specified by the user.
SingleState & ListState
By considering the problem at hand: making a store web application, one can readily conclude that the user will only need two types of states regardless of the data units that'll be preserved. The first one is a state of a single entity, like "LoggedinUser" for instance, which we may call a SingleState. The second one is just a typical AppState with the SingleState as the type of the Entity value propery, which we may call a ListState.
As mentioned before, inherited AppStates are distinguished by three things: the Entity, the Controller, and the overridden methods. For instance, in order to make a SingleState, we ought to change the key type of the Entity to a constant string rather than an arbitrary one (which is easly implemented with TypeScript). In addition we shall dismiss the "addEntity" method and let the user set the value by the class constructor instead.
The end-states, that are ultimately used by the user to store data in the RootState, are created by specifying the structure of the SingleState value. For example, the structure {user_id, username,... etc} could be used to define a User end-state by specifying it as the type of the SingleState Entity value. Moreover, the creation of end-states should be generic; it shouldn't require more than defining the structure of the data. In other words, we should avoid the hell of inherited classes, by using a factory that takes a structure type, as a generic parameter, to create for us a ready to use SingleState, of the specified structure, and ListState, of the created SingleState.
StateFactory
The whole purpose of this class is to dynamically generate the AppStates that are meant to be used by the user. Without it, we will tediously declare and define several classes and write the same code over and over again: UserState, UserListState, PublicateState, PublicationListState,... etc. On the other hand, by using this class we will just need to define structures (data units), and pass them to a factory to which the process of end-state creation is delegated.
RootState
Finally, the TRUE StateManager, that’s mentioned previously in first place, is preferred to not be included in the abstract implementations and rather to be defined by users manually. It could be derived from AppState or easily generated by the generic ListState facility.
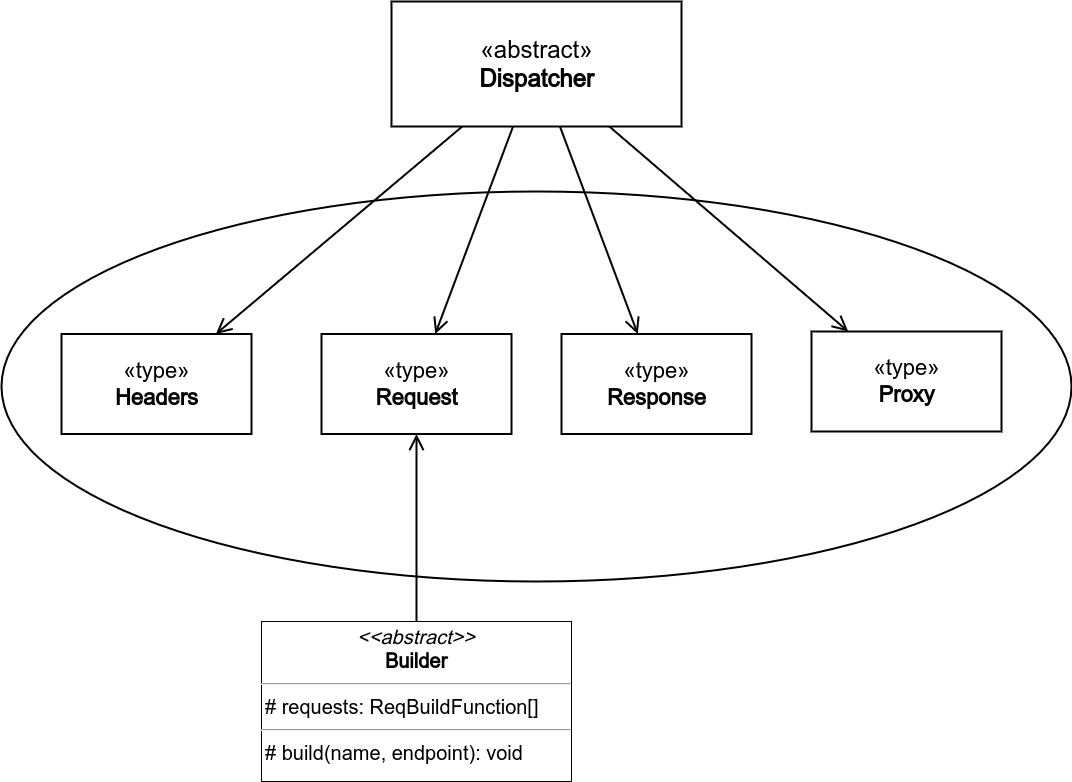
RequestDispatcher
RequestDispatcher is considered as a bridge between the frontend and the backend; the frontend shall use it to retrieve data from the Database, and save the frequently used data by using the StateManager. It's up to the user (UIPainter) to decide whether it's worth retrieving the data from the StateManager or updating it and get the up-to-date version by using RequestDispatcher.
This component basically contains two elements: Dispatcher & Builder. Technically, the both objects contribute in constructing the (HTTP) request; the Dispatcher specifies requests proxy and headers, while the Builder specifies the URL, the body and the method.
In general, Dispatcher has only one method, that's used to dispatch different requests, with only one parameter of type Request (an object with URL, body and method as its only properties). It may also contain functions to return and replace configuration values. On the other hand, Builder has dependency on the Endpoint type of the Server component to retrieve the right request URL path associated with its method type.
A full-fledged request object is built in two stages:
The first stage takes place in the constructor of the Builder where it generates a ReqBuildFunction from each X-related endpoint, retrieving them from the backend, and stores it in a local variable (X can be user, publication, review, ...etc). ReqBuildFunction takes two parameters, the first one is the body of the request whereas the second is a variable-length argument list; the first just gets assigned in the request object, and the second is used in formatting the URL path.
The second stage builds full-fledged requests by invoking ReqBuildFunctions from the first stage with different inputs. Each class derived from Builder ought to build its set of methods, by using the inherited build method, which users (UIPainter and/or Dispatcher) can invoke with the suitable data in order to build the desired request objects.
These stages helps a lot in maintaining the functionality of RequestDispatcher; as each method prescribe the required data to fulfill the request in its parameters.
UIPainter
This component serves as a guide which leads any UI framework, a decision that can be taken throughout the project development lifecycle, to the way to be thoroughly integrated into the project. Maybe the best way to describe this component is to consider it as a generalized mold that reshapes any UI library, even the ones do not currently exist, to be more suitable and amenable to be plugged into the architecture.
UIPainter is constituted by a subprogram storage and two facilities: View, Screen, and UIApp. Where an application can have many screens, each screen contains zero or more views, and views vary in type. The facilities (Screen & UIApp) may be described here, View, however, shall be elaborated in the following sections.
UIApp main purpose is to start and close the application, Screen, on the other hand, is used to establish the required files/objects needed by UIApp in order to display on starting. There are barely an abstract implementation for these classes, so it would be reasonable to discuss them in some context. HTMLApp, for instance, may implement UIApp.start method by starting an HTTP server hosting HTML files. On the other hand, HTMLScreen may implement Screen.create method by writing an HTML file in the root directory specified by HTMLApp.
UIApp has three methods: addScreen, start, and close. Whereas Screen has: addView, create, and init. Screen.init is a protected method that gets invoked by the constructor; if it’s not implemented by derived classes an error is threw in runtime. For instance, HTMLScreen.init shall specify the head and the body of the HTML file.
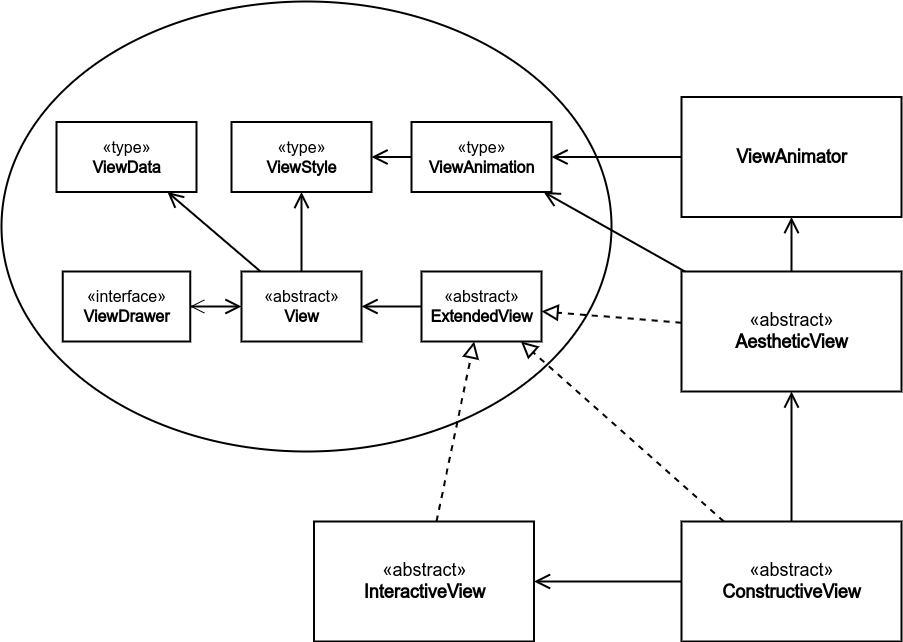
View Types
We may classify the views into three classes by which we can construct any UI system: constructive, interactive, and aesthetic. Each class has its own characteristics, however, they share some and even may intervene to produce a multi-purpose view.
There may be some properties and/or methods in common like: id, dimensions, a method to draw the view, and a method to destruct it. Which will be consolidated by a general class "View". Nevertheless, each type has its own characteristics and purpose; the purpose of a constructive view is to make and construct a container that collects several views, of any class, together; which is very convenient for real world UI problems. Whereas an interactive class purpose is to employ user inputs and/or different events into the UI of the application; it literally gives life to the UI. Last but not least, the aesthetic view purpose is to ornament the UI with, for instance, notifications, pop-ups, animations, images, ...etc.
All types of views should be generic on ViewData and ViewStyle, in order to make it extendable by the user.
Abstract View
A three values ought to be specified while constructing a view: data, style, and drawer. Each, but the drawer, has a getter and setter methods within the view object. The view delegates to the drawer the following functionalities: View.draw, View.update, and View.destroy.
Moreover, the data of a view must contain id attribute whose value cannot be changed; View.setData(obj) throws an error if the parameter “obj” has id attribute. Similarly, parentId attribute may be assigned before constructing the view object, however it’s not compulsory and can be changed with View.setParentId method as soon as the view is not drawn yet.
Along with the three drawer methods, view objects have the following events: onDraw, onUpdate, and onDestroy. Each of which has its setter method within the view object, and they get invoked locally in draw, update, and destroy methods, respectively.
Last thing to mention is that View.setData and View.setStyle shall automatically invoke View.update in case the new data/style has new values rather the already assigned ones. And that View.update and View.destroy have no effect unless the view is drawn.
Dynamically Extended Views
The three types of views, in the following three sections, are not inherently derived from the abstract View, rather they extend its behavior dynamically; they store the associated View object locally, whose value is assigned in the constructor, and extend its behavior by delegation.
For example:
abstract class ConstructiveView<V> extends ExtendedView<V> {
private children: ExtendedView[];
draw() {
this.myView().draw();
foreach view in this.children {
view.draw();
}
}
}An ExtendedView expects View object value to be passed in the constructor, and it defines two methods: ExtendedView.myView() and ExtendedView.draw(), the former returns the passed view object while the latter invokes View.draw() method (typically, it gets overridden in the extended derivatives).
Constructive View
In order to make the architecture amenable to design a vivid world of views, we ought to assign one more responsibility and make an object creation constraint. The constraint states that no view object, except the constructive, can be created without being attached to a constructive view (its parentId property is assigned to some constructive view id); meanly, there should exist a constructive view, in advance, that's waiting for any other type of views to be attached to it. Whilst, the constructive view has one more responsibility which is the searching mechanism.
Consequently, any application should have at least one constructive view which, in implementation, we shall call the "root". To get a specific view in the whole application we may use the search method in the root. The searching mechanism simply visits every view in the construction (including the constructive view itself) and compares its id to the required view id. If the required view is found, it gets returned by the function, otherwise it returns no object (NULL).
Interactive View
This class only extends View to be able to collect various event handler functions and apply each one when its corresponding event occurs. Mainly, it has the following two methods: setEvent and onEvent, each takes two parameters: eventName of type string, and callback of type InteractiveViewCallback (which is just a function with one parameter of type View).
InteractiveView.setEvent(name, callback) declares a new event, or overrides an existing one, with the passed name, and then defines it by giving it a value of an array with the passed callback as its only element. On the other hand, InteractiveView.onEvent(name, callback) only pushes the passed callback into the array of the named event if it exists, throws an error otherwise.
Lastly, InteractiveView shall apply these events handlers after the drawing process, and therefore it extends the draw method to invoke InteractiveView.apply after drawing. InteractiveView.apply only throws an error, in the abstract implementation; it ought to be overridden by concrete objects.
Aesthetic View
Any view that’s neither constructive nor interactive is considered as an AestheticView (TextView, ImageView, ...etc). Moreover, AestheticView class encapsulates the use of ViewAnimator (it’s described in the following sections); it defines methods like: animate and animateOnDraw that delegate the whole process to a ViewAnimator object.
However, all methods throw an error unless the user set the animator object with AestheticView.setAnimator(animator: ViewAnimator).
View Drawer
As mentioned before, the main purpose of this component is to make the architecture independent of any UI framework, and so to be as portable as possible (it can be used for a web, desktop or mobile application). To further this purpose, we shall use the "Strategy Design Pattern" in order to delegate the draw function in View Objects to another dedicated object, which draws the UI by using a specific framework. In addition, a view object instance shall pass itself to the delegated strategy object, so it can access the required data of the view and/or invoke views event handlers.
This design is considered as a receptacle through which different frameworks can be plugged into the architecture; And so it extents the architecture to a wide variety of applications.
View Animator
ViewAnimation objects constitute of three attributes: from, to, and durs. The first one is of type ViewStyle, the second is an array thereof, and the third is an array of integers representing durations in milliseconds. On the other hand, ViewAnimator objects methods use ViewAnimation properties and View.setStyle method, thereby applying the stages of the desired animation.
ViewAnimator has two methods: animate and animateTo, both take two parameters of types: View and ViewAnimation. The only difference between the both is that ViewAnimator.animateTo excludes the from stage. Basically, ViewAnimator.animate sets the style of the view to the from attribute then invokes ViewAnimator.animateTo with the same parameters values.
ViewAnimator.animateTo method loops over the to attribute of the passed animation object, and invokes, in each iteration, View.setStyle method with to[index] as its parameter value after durs[index], multiplied by index, milliseconds (where index is the loop counter variable). However, the durs array may not have the same length as to array, moreover, it may not be assigned at all (equals null/undefined). Therefore, ViewAnimator.animateTo handles this by using one of the three values: durs[index], durs[0], or constant (1000, for instance) (multiplied by index), with respectively descending priority.
In Implementation Decisions
Although the blurry of the line, in general, that separates between design and implementation in software development, the components described so far are abstracted as much as possible to leave, hopefully, no significant design decisions for implementation stage (the implementation is mostly derived classes from the abstract module. Moreover adapters, proxies, and alike may be needed). Nevertheless, this component (UIPainter) doesn’t, so to speak, hedge some design decisions that are usually vital.
And so, this section is worth mentioning to keep in mind considering what may go beyond the abstract modules described here. For example, UIPainter implementation shall use the Facade design pattern in order to effectively use ViewDrawer; without the facade pattern, ViewDrawer merely bestows some flexibility on the architecture.
interface DrawersFacade<V extends View> {
div(): ViewDrawer<V>;
text(): ViewDrawer<V>;
button(): ViewDrawer<V>;
…
}
class PureJSDrawers implements DrawersFacade<HTMLView> {
…
}
class ReactDrawers implements DrawersFacade<HTMLView> {
…
}Written by Mahmoud Ehab Abdelsalam in April 2023, after receiving a BSc degree in Statistics & CS from Helwan University at Cairo. I wrote it in the spirit of learning and enjoying the art of software design and development, and just before enlisting in the military.