



AGI Is Already Here—It’s Just Not Evenly Distributed
Or: why you should learn to prompt AI models

I. Never underestimate the value of a good prompt
You may have heard me say that prompt engineering is dead. Turns out it was just sleeping.
This is a redemption post for that bad take. It's also a hopeful one as we’ll see. And a warning: there's no time to lose. As AI models get better, your chances of belonging to the AI-poor crowd (those unprepared to leverage AI for their benefit) grow as a function of your lack of money and lack of prompting skills. Neither you nor I will win the lottery anytime soon so I’ll focus on the latter today.
The clickbaity headline suggests AGI is here. It isn’t. I lied. Well—sort of. I’ll have to argue my way there, and if I fail, you’re free to call me a liar. For the skeptics: I don’t believe today’s top AI models (e.g., o3) qualify as AGI. I like to say, “No AGI is dumb at times.” I assume we can all agree ChatGPT doesn’t quite meet the bar.
But even an AGI denier like me must concede that prompt wizards have a knack for coaxing these models, pressing the right buttons until they perform like general intelligences. If the capability of an AI model depends on whose hands are at the wheel, then, eventually, AGI will be real for those talented magicians and science fiction for the rest of us mere mortals. Perhaps the time is now: In the right hands, o3 (Deep Research) is never dumb.
Anyway, as much as I enjoy wasting time on fruitless philosophical debates, I’ll set AGI aside and focus on something more practical: What do these AI masters do that others don’t? How do they prompt AI models to say, think, and do exactly what they want? How do they turn an unreliable chatbot into a PhD-level research assistant?
I can’t reveal their secrets. I’m not one of them. But I can convince you that you should want to be one. Become a prompting wizard.
You're probably wondering why I changed my mind on prompt engineering. The answer is OpenAI's Deep Research. The second-hand testimony I'm getting (including, for what is worth, from OpenAI staff) is quite unanimous: Deep Research is really good—if you know how to prompt it. Slight tweaks in your prompt can yield outsized gains in performance. Or the opposite. Those who know the right tweaks will see an incredible return on their investment—currently $200/month.
II. The complex world of prompt engineering
The value of good prompting wasn’t always so obvious. The original ChatGPT (powered by GPT-3.5) was a fairly capable chatbot but not more than that. If you asked it to delve into the intricate tapestry of events and consequences woven by the Second World War, it might have given you a passable essay. Anything more complex was a miss.
The original ChatGPT version was a mediocre writer. A mediocre coder. A mediocre scientist or mathematician. Your well-crafted prompts could hardly move it away from the mediocre pit of the statistical average. Then we got GPT-4, GPT-4o, o1, o3-mini, and now Deep Research (which is built on top of the full o3). The performance of these models as a function of prompting skills has changed with every iteration.
Some (myself included) argued that prompting would matter less over time. The reasoning? As AI improves, it should get better at inferring intent, even from poorly worded or incomplete queries. I was wrong. (I still think my prediction was early rather than outright wrong and will eventually be proven right—but for now, it isn’t.) AI models are getting better, but they aren’t becoming more accessible for inexperienced users. Extracting their full potential still requires strong human-machine prompting skills. In fact, because the models are more powerful, the potential gains grow, as does the expertise needed to squeeze out those last drops of performance. So prompting doesn’t just remain important. It matters more than ever.
A simple analogy: Asking Deep Research instead of GPT-4o without any prompting skills is like replacing a clueless undergrad with a brilliant PhD assistant except both only speak Japanese, and you only know English. The PhD assistant has far greater potential, but your ability to access it is capped by your lack of fluency. As a result, you get little out of either.
In that fictional scenario, you’d be desperate to learn Japanese. In the real world, you should be just as eager to master prompting.
So I was indeed wrong. But here’s the interesting part: I wasn’t fully wrong. The default behavior of a better model—without any expert prompting—is also better. So was I wrong because good prompts matter a lot? Or right because they don’t matter that much? How do we reconcile these seemingly conflicting facts? Deep Research helped me figure it out. It didn’t invalidate my stance; instead, it revealed that the relationship between prompt quality (as a proxy for prompting skill) and model performance is more complex than I initially thought.
This requires a graph so I plotted one:
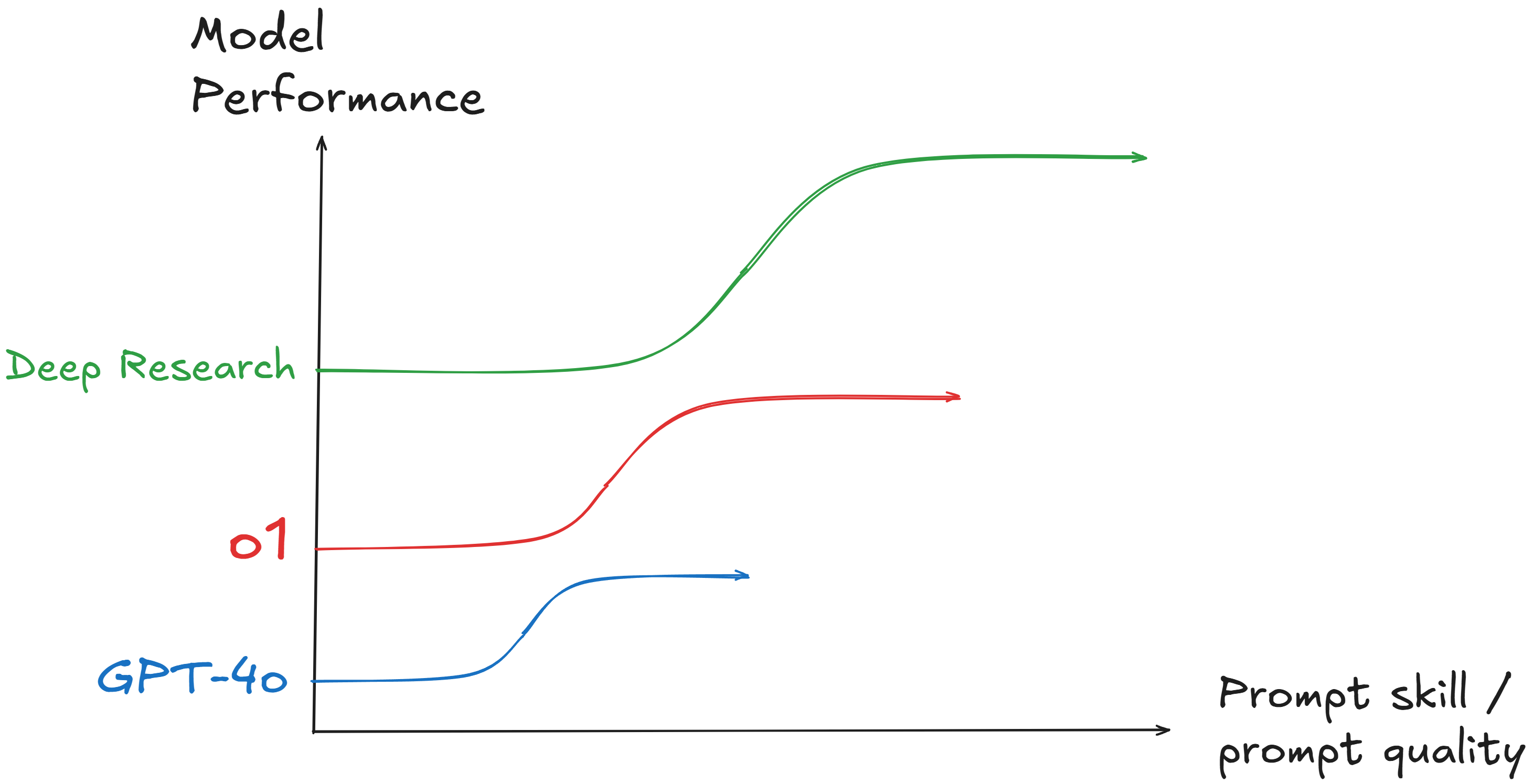
Don’t be afraid if the graph looks indecipherable. I’ll spend the rest of the post explaining why it’s so important.
On the x-axis, you have prompt skill/quality. On the y-axis, you have model performance. I’ve drawn three curves for GPT-4o (blue), o1 (red), and o3 (Deep Research, green). Note that there aren’t any numbers on the axes or curves. That’s because this is a proof of concept more than a quantitative representation (I don’t have any empirical data).
What these curves represent is the variation of model performance as a function of prompt skill. Two relevant details that should be immediately apparent: the curves are s-curves (flat-slope-flat) and they have different sizes (the y-intercept, the asymptote, and the height/length of the slope are different). This is only a rough approximation of the real thing but I believe it to be a good one.
Let’s see if this graph helps me convince you of the value of good prompting skills.
III. Prompt quality and model performance
I should start with a caveat: prompt quality/skill and model performance can’t be defined as a single dimension but as an overarching variable comprising many factors.
Several factors influence the quality of a prompt, and reducing them to a single axis is an oversimplification. For example, you might excel at managing people, which makes you great at providing context and clear instructions. But that doesn’t mean you’re any good at steering an AI through its unpredictable latent space—a skill that requires technical finesse. Few have mastered all aspects of prompting. Most people lean into the one thing they do best.
Here are a few key factors I’ve bundled into the x-axis without changing my core argument:
Type of model: Prompting a chatbot isn’t the same as prompting a reasoner or an agent. Each requires a different approach.
Context richness: Some queries need just a quick question, while others demand extensive background (sometimes, your entire life story).
Length: Modern AI models handle long context windows, but more isn’t always better. Expanding too much—like uploading a year’s worth of consultancy projects for a summary—can lead to diminishing returns.
Style and formatting: How information is structured affects how well the model processes it.
Specific techniques: From role-playing to chain-of-thought prompting, various methods unlock different capabilities.
Not all of these factors matter equally. The best way to understand what “quality prompting” or “good prompting skills” really mean is to experiment. There are a few solid blogs and podcasts on the topic, but no universal manual. The best prompt engineers are still figuring it out. You may or may not hit the performance asymptote that prompting wizards effortlessly hit, but that shouldn’t concern you. Just give it your best shot.
The same applies to model performance on the y-axis. There are numerous benchmark categories—math, coding, science, reasoning—each with different levels of difficulty. New ones emerge every year (FrontierMath, Humanity’s Last Exam, etc.), making it impossible to capture the full variability in a single metric. That said, I believe AI models have an equivalent to the g-factor in human intelligence. You won’t have one model that’s best at math, another at coding, and another at perception. Convergence is inevitable. The best chatbot will be the best reasoner, which will be the best agent. A single axis for model performance captures this idea well enough.
IV. Model performance is an S-shaped curve
Now that we’ve understood the axis, let’s go with the S-shaped curves. Each follows the characteristic sigmoid pattern: flat (initial plateau), slope (rapid improvement), and flat again (performance ceiling).
The first flat section reflects the idea that when you’re bad at prompting, the model is doing most of the heavy lifting. Your input still matters, but there’s a baseline level of competence the model will maintain, even if your phrasing is clunky or your grammar is a mess. That’s because the model isn’t just winging it—it’s been trained on a massive web-scale dataset, fine-tuned with human-curated examples, reinforced with its own responses, and kept in check by a system prompt that stops it from going rogue or saying weird stuff (like telling you that your prompting skills suck).
Even under the most adverse circumstances, the model will try its best to be helpful. You can throw in a vague, half-formed request, and it’ll still produce something coherent. But that doesn’t mean you’re getting the best it can offer. Just the best it can do despite you.
The slope represents the phase where improvements in your prompting skills translate into significant gains in model performance. This is where your ability to phrase things clearly, understand the model’s latent space, and apply techniques like “let’s think step-by-step,” chain of thought prompting, or telling it to “wait” after it’s finished reasoning, etc. can make a noticeable difference. This slope section is why I’m writing this article in the first place: learn to climb the hill and you will be able to 2x the return on investment of using AI models (the 2x figure is made up, it may well be 10x).
The second flat section reflects an unavoidable truth about intelligence: it has limits. No matter how clever, structured, or technically refined your prompts are, you can only squeeze so much out of a given AI model. You don’t turn a Fiat into a Lamborghini by adding leather seats, scissor doors, and a loud exhaust. Likewise, no amount of prompt engineering will make GPT-4o perform at o1/o3 levels.
The model’s maximum theoretical performance is asymptotic—there’s a hard cap, even if we don’t always know exactly where it is. Yes, “sampling can prove the presence of knowledge but not the absence,” but that doesn’t mean the ceiling isn’t real. Whether or not the best prompt engineers can reach it, it’s there.
In reality, the curves aren’t a single smooth S-shape but more likely a sequence of concatenated S-curves. Each new slope represents a breakthrough—a new technique that unlocks a discrete jump in model performance. But this detail doesn’t really matter. The simplified S-curve is good enough to convey the core idea: reach the slope, and you’ll be fine.
V. When the subject is the bottleneck
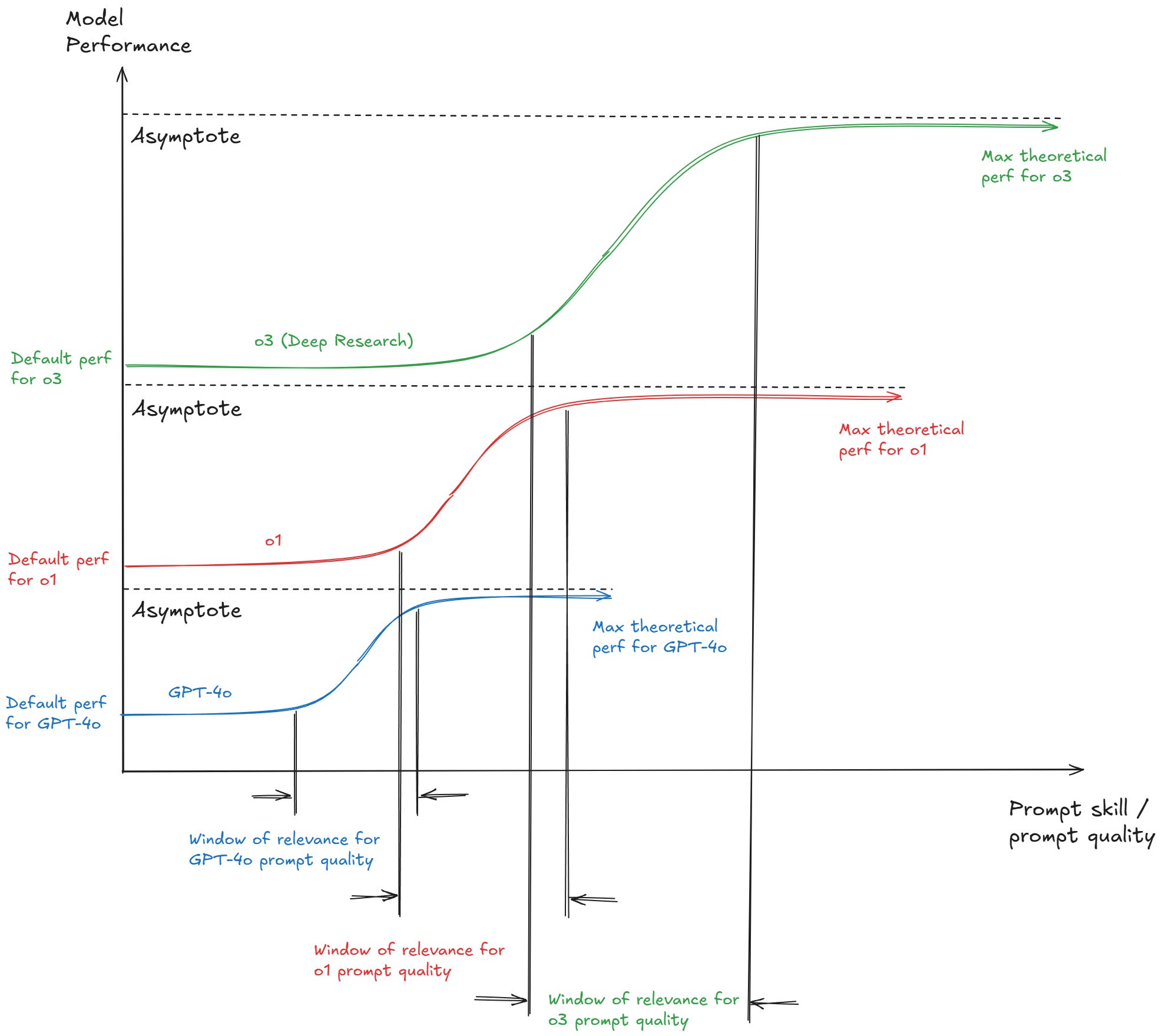
Finally, let’s go over the specific characteristics of each of the S-curves for different AI models: y-intercept, asymptote, and height/length of the slope.
The value of the y-intercept grows as the model improves. This is the most intuitive aspect of the graph: If your prompting skill is null, then the better model produces better performance. This is part of why I used to think that prompting would matter less over time: models will be better by default and better at doing the heavy lifting of understanding you. I was right about the first part. It’s the second part that I was wrong about.
The asymptote of an inferior model sits lower on the y-axis than the default performance (y-intercept) of the next model. This means a noob can get better performance out of o3 than an expert out of o1. This isn’t always strictly true, but OpenAI (and others) ensure that each new model reaches a level that even expert users can’t achieve by optimizing prompts on the previous generation. That’s how they sell access—by making the next model so much better that skill alone can’t bridge the gap.
Advances in pre-training, post-training, data quality, and architecture all push the ceiling higher with each iteration. For non-experts, the jump between generations is even more dramatic. Using o3-mini after only having tried GPT-4o, for example, is like leaping from the start of the blue curve to the start of the green one. Quite the upgrade for the noob.
Don’t get me wrong, good-enough models will get it right if you input a simple query but we’re talking here about performance on the hardest tasks possible. Interestingly, most people are unable to come up with queries that grow in complexity parallel to model intelligence, which means that at some point the bottleneck of AI performance won’t be the model or even your prompting skills but your ability to come up with a hard enough question. That’s a mix of knowledge and intelligence, which we can’t improve as easily as prompting skills. This is a fundamental paradigm change that will define the coming years of human-AI interactions.
The slope section stretches longer and climbs higher as models improve. Think of Deep Research as a PhD assistant and GPT-4o as your lifelong friend who knows nothing about science. The quality of their responses depends on how well you can extract the knowledge hidden in their minds. With your friend, the ceiling on scientific questions is obvious and easy to hit. You’ll run out of useful answers fast. But with the PhD assistant, the limit is much further away. The better you are at prompting, the more you can pull from its expertise before reaching that ceiling.
The window of relevance for prompting skills grows as the intelligence of your recipient increases. Ask your PhD assistant a well-structured, complex question, and it will do magic. Ask your friend and he’ll just stare at you, clueless.
So we arrive at the same conclusion: your ability to ask hard questions and frame them effectively will eventually be the bottleneck. This isn’t unique to AI—it’s how all tools work. You can’t calculate much with an abacus, but the limits of a scientific calculator are the limits of the scientist using it. A tricycle won’t take you far, but an F1 car’s speed is dictated by your reflexes and the strength of your neck muscles.
Every tool advances until the constraint is no longer the object but the subject.
VI. Carry that graph with you everywhere
You only need to remember the graph. It contains everything you need to remind yourself why prompting skills aren’t less important, as I once thought—but more.
If you know nothing about good prompting practices, you’ll still be fine. The ever-improving default capability of AI models will carry you forward regardless. The rising tide lifts all boats. But if you actively develop your prompting skills, you won’t just rise with the tide—you’ll unlock performance levels that seem impossible. Some boats are lifted more than others. A few rise so high you can barely see them. Your choice.
And as a final thought—nod to the bold headline I’ve chosen—I’ll take the liberty of repeating something I can’t prove, yet hope I’ve persuaded you to believe is true: AGI may or may not yet be here (depending on your definition), but once it happens (regardless of your definition), it won't be evenly distributed.
Who gets it—and who doesn’t—will depend on prompting skills, intelligence, and knowledge.
I didn’t lie, did I?
Climb the slope.





Alberto if this is some subtle marketing for your new prompt masterclass sign me up hahaha. In all seriousness, there must be common factors that make a good prompt particularly within classes, eg, llms, lrm, etc. Very keen to hear more about improving prompts considering this will be such an impactful skill over the next year or two. I've noticed that some people truly can pull off what seems like magic with these tools, whereas others as left summarising news articles or youtube videos...
Wonderful. Thank you!
Would anybody be open to sharing impactful resources connected to prompt engineering? I appreciate it very much.