

Issue #15: Can Activity Schemas Replace Star Schemas?
Issue #15: Can Activity Schemas Replace Star Schemas?
Can Activity Schemas Replace Star Schemas, SQL:2023 Standard, Change Data Capture, Publicly Available Real-Time Data Sources and Software Estimation

This week have:
Can Activity Schemas Replace Star Schemas?
What’s new in the SQL 2023 Standard
PyCon US 2023 Talks Are Now Live on Youtube
What is Change Data Capture?
What are Some Good Publicly Available Real-Time Data Sources?
Census Releases a dbt Package for Reverse ETL
Software Estimation: The Work is Never Just “The Work”
Can Activity Schemas Replace Star Schemas?
You can make a good argument that everything in a business can be modelled as a series of events that can be tracked, for example, business processes such as:
Sales Transactions
Employee Status Changes (Hiring, Promoting and Resigning)
Supply Chains
Project Management
Marketing Campaigns
Application Monitoring
Can be modelled and captured as a series of events. So maybe data modelling should lean more into this? In some ways, Star Schemas already do this, as fact tables are often a list of events, but often a fact table is made for each kind of a event, which can be difficult to maintain if you have dozens of events.
But what if we just had one table of five to ten columns with all the business events in it? Activity Schemas does exactly that by only mandating a single “Activity Stream” table:

You’ll likely want to add an entity dimension and possibly some more mandatory metadata columns (for example, “deleted” for GDPR requests or “source_system_id“ to track lineage) to the Activity Stream but that’s it; your data model is in theory ready to create reports and dashboards:

Star Schema Hell and Event Utopia
While the above may sound like a crazy idea to some, the current situation in most large organisations using classic dimensional models isn’t pretty, as no-one wants to query or make significant changes in this kind of mess:

Activity Schemas in theory cut down on the large architecture and engineering costs of building a bespoke enterprise data model that often looks like the above, as you are modelling only a few tables rather than hundreds or thousands.
Even better, new events can be added to the Activity Schema with little or no work, rather than doing a data model refactor that can take days to months to complete.
Also, for data discovery this is a massive boon, as you don’t have to scour through hundreds, if not thousands of tables for one piece of data and don’t have to worry about data being lost due to being overwritten or deleted (unless GDPR strikes).
Finally, if we all adopted this schema, we could reach some kind of modelling utopia where all departments and organisations are using the same schema, which would make data sharing and governance much easier.
Problems with Utopia
For Utopia to work, everybody would need to get on board with Activity Schemas, as this is a massive shift in how you design data models. The political cost of change could be significant in a large organisation.
I doubt a large organisation will want just one Activity Stream for security reasons (keep finance tables on a different network) and to allow for independent deployments of Data Products.
Also, for Activity Schemas to work well, your Analytical Processing Systems (Databases, Lakehouses) need great support for JSON columns and most of your analysts need to feel comfortable querying SQL and JSON columns.
As seen in the new SQL standard, covered in the next section, the SQL language is getting better at storing and querying JSON, though you may find legacy systems do not support it as well as native types.
Popular Business Intelligence applications are designed for mainly ingesting Star Schemas, so you may see some issues with performance and extra expertise required to extract JSON data, such as needing Power Query knowledge to extract JSON data in Excel. This isn’t a large blocker in my experience of using JSON columns, as you can create views on top of the Activity Stream, but there is a trade-off here you have to make.
I also feel we may lose some of the benefits of Enterprise Data Modelling if we just use an Activity Schema with Analyst created views: Enterprise Data Modelling sets a long-term, consistent model that reduces duplication and misuse, as there is a very real risk of duplicated, inconsistent metrics and reports without an opinionated core model to use.
To combat the above issue, you could either use a Metrics Store, a more controlled process for making views or have a compromise solution of making a Activity Schema the base for a Star Schema.
Event Driven Future
Even with all the possible problems I’ve stated, I am keen to spend more time with Activity Schemas, I think they can dramatically simplify data models if used right and move us towards a more functional programming way of doing Data Engineering by having an immutable log of events at the center of our data model.
I think Activity Schemas will work best if your organisation has adopted an Event Driven Architecture and / or Real Time Streaming for most of your software systems, as Activity Schema are all about capturing and querying events. I feel we’re heading towards a more event-driven future and Activity Schemas are perfectly placed for this future.
Though I expect a much harder migration if you’ve got lots of aggregated reports imported into your data model, as these will likely not be modelled around events.
If you’re interested in modelling for data that changes a lot but less of a dramatic change compared to Star Schemas, I’d also recommend looking at Data Vault modelling, which doesn’t require JSON columns and is still designed to be highly flexible, though it has its own limits.
There can also be a case for having “One Big Table” with a column for every attribute, which is popular and also reduces the size of data models. Though you can end up with dozens, if not hundreds of columns, making the table difficult to read. It’s also harder to replace or update event attributes and you may run into similar performance issues with Business Intelligence applications.
If you like to read more on Activity Schemas I recommend:
Ergest Xheblati has real world examples of using Activity Schema.
Lauren Balik compares Activity Schema against “Data-in-a-box“ SaaS tooling.
I suspect this is a controversial topic, so feel free to leave comments, I’m quite happy to update this based on feedback.
SQL:2023 is finished: Here is what's new
ISO SQL:2023 standard is out! While ISO standard updates may not seem like the most exciting news to write about, I think they are interesting in that they can show trends in database usage or at least trends where users would like gaps filled in SQL’s syntax.
Peter Eisentraut, a core member of the popular open source database PostgreSQL, has written a summary of changes so you don’t have to spend money to buy the standard. You might be also interested in when PostgreSQL gets SQL:2023 standard functionality.
My main takeaway from the latest standard is a move for SQL into areas that are traditional places for NoSQL databases: querying JSON and graphs. While querying JSON with SQL isn’t new (1, 2), the standard expands on what has gone before.
PyCon US 2023 Talks Are Now Live on Youtube
The annual United States Python Conference always has a few great talks on data topics and general good programming practices and with over 140 talks uploaded, you are likely to find something that interests you.
What is Change Data Capture
It feels like Change Data Capture (CDC) is now becoming an essential part of any Data Platform, providing a reasonably easy way of moving source data to destinations in near-real time.
Popular Data Engineering writer and consultant Ben Rogojan gives reasons why CDC has become popular and also offers a number of tools and techniques on how to implement it.
Introducing dbt_census_utils: The first dbt macros for data activation
Census is a Reverse ETL product, trying to make it easier to get data from an Analytical Database / Lakehouse back to their source system.
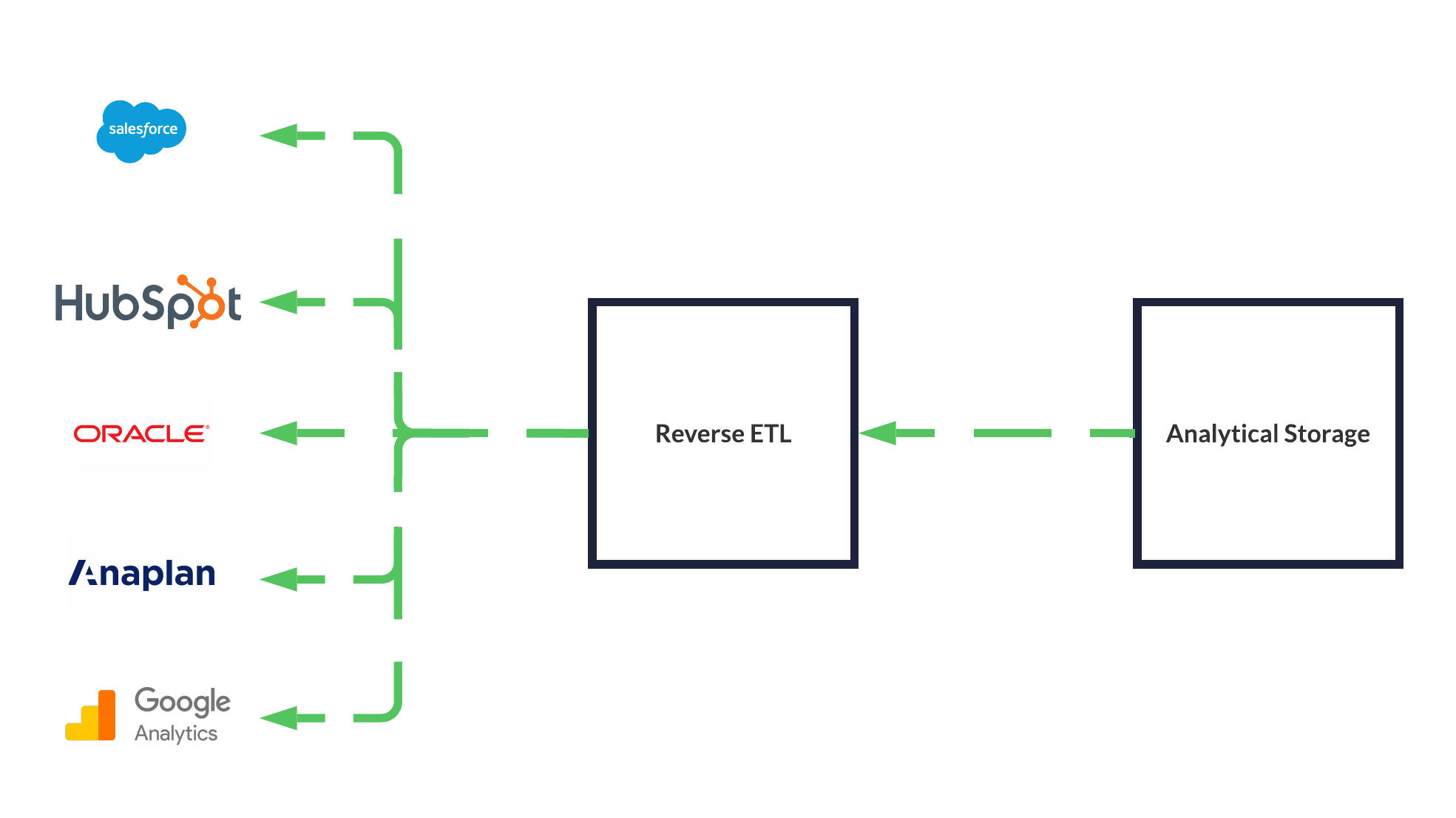
So a typical use case would be moving data from Databricks or Snowflake back to Salesforce, Oracle Netsuite, Google Ads and more so you can get high-quality analytical data back to business departments like Marketing, without them having to open up a database client or Business Intelligence application.
This article talks about how Census made a dbt package so you can integrate Reverse ETL into your SQL pipelines, which in theory sounds pretty cool, though competitor Hightouch has some dbt integration too.
I talk more about Reverse ETL in my Data Pipelines article.
What are Some Good Publicly Available Real-Time Data Sources?
A Reddit discussion on finding good real-time data sources, which I personally found rather tricky until I came across this thread, especially if you don’t want to build another stock or crypto data feed.
The work is never just “the work”
Web Developer and Browser Extension Creator Dave Stewart has written a postmortem on a software project that went 460% over the original estimate, with some beautiful graphics to explain where all the extra time went.
I love reading about estimating software, as it’s more of an “art” than a “science” that you can never perfect, so I’m always looking to get better at it. Though I’ve seen a few organisations try to use past estimations to make forecasts in the future.
If you’re interested in this topic, I talk about it some more about software estimation in Issue #11.
Sponsored by The Oakland Group, a full service data consultancy.
FYI, there's also an Activity Schema dbt package for implementing the relationship transformations of the activities in dbt: https://github.com/tnightengale/dbt-activity-schema